网站做公司外贸营销型网站设计
深圳锐科达SIP矿用电话模块SV-2801VP
一、简介
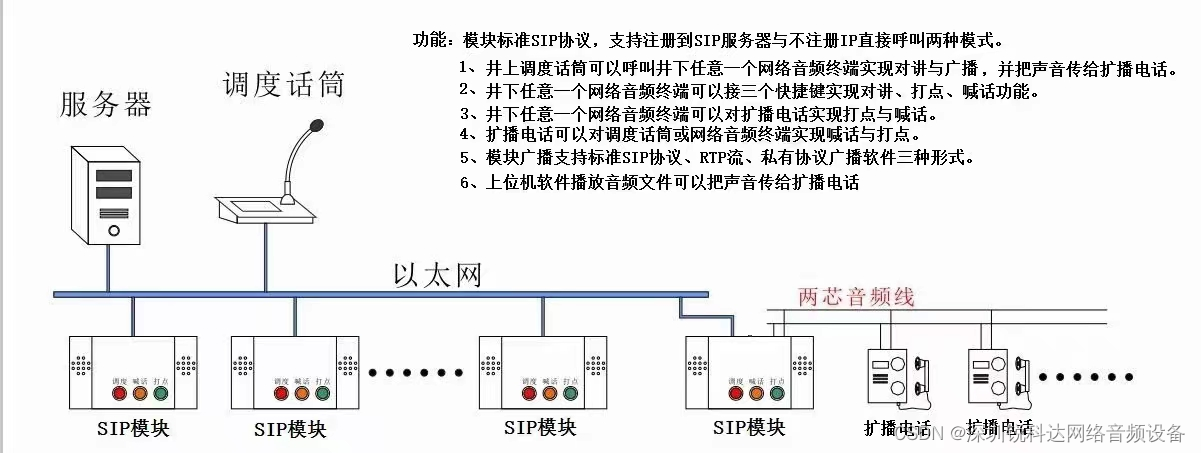
SV-2800VP系列模块是我司设计研发的一款用于井下的矿用IP音频传输模块,可用此模块打造一套低延迟、高效率、高灵活和多扩展的IP矿用广播对讲系统,亦可对传统煤矿电话系统加装此模块,进行智能化数字化升级。
SV-2800VP系列模块具有网络对讲、广播喊话、皮带打点等基本功能。同时还支持联动传统双线矿用电话、CAN总线控制联动和定制IO传输等功能。
二、功能描述
基本功能
- SIP对讲功能
与另外的IP矿用电话或者调度主机一对一双向通话,可以作为:
主叫:通过快捷按键呼叫
被叫:按键应答或者自动应答
- IP打点功能
18123651365微信
可以往其他多个IP矿用电话发送预设的音频
- IP喊话功能
可以通过mic,对其他单个、多个或者全部IP矿用电话单向喊话
- 音频播报
空闲时,播放来自其他IP设备的网络音频(打点或者喊话)
收到紧急音频,可以中断其他操作,直接播报紧急音频
模拟矿用电话扩展功能
- 兼容模拟扩音电话的打点和喊话
可以对模拟矿用电话打点、喊话
可以将模拟矿用电话的打点或者喊话声音,送给其他多个IP矿用电话
- 语音中继模式
可以作为中继设备,调度中心可以对模拟矿用扩音电话单向喊话
可以作为中继设备,调度中心可以与矿用扩音电话实现半双工双向对讲
CAN总线扩展功能
- 通过CAN总线传输IO干接点应用
- 通过CAN总线控制IP矿用电话内置音频文件播放
- 通过CAN总线传输半双工音频(备用)
其他扩展功能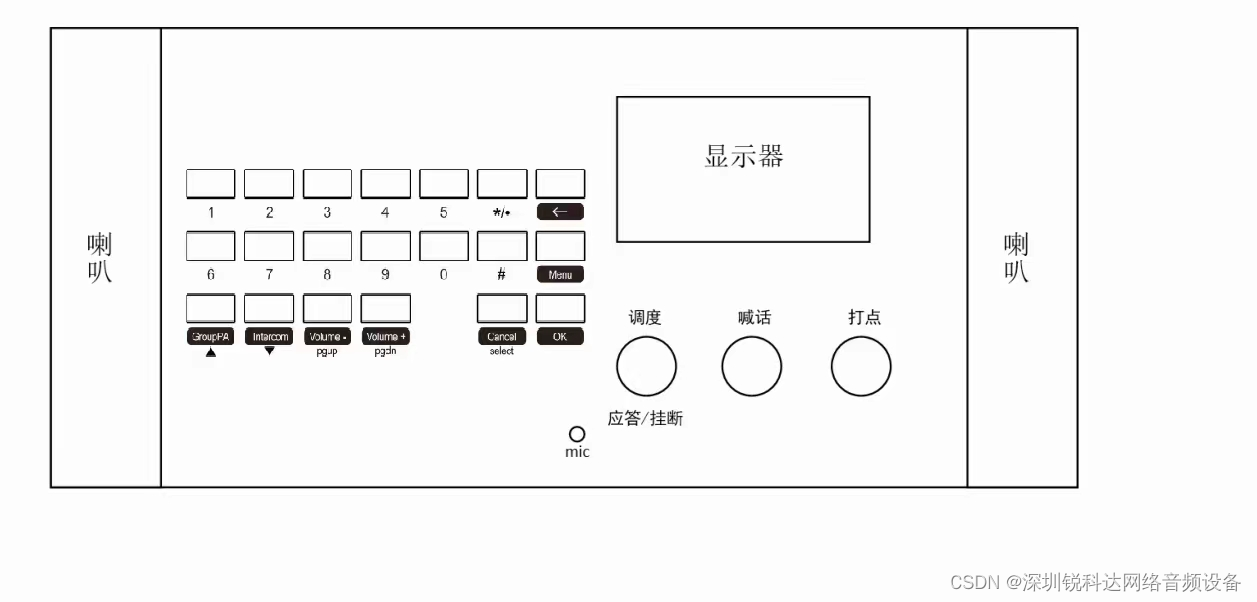
- 摄像头连动
与调度机对讲时,获得指定摄像机的视频,与语音流一起送给远端的调度主机,实现可视对讲
- 内置音频文件播报
通过网络或者CAN总线,控制IP矿用电话内置音频文件播放
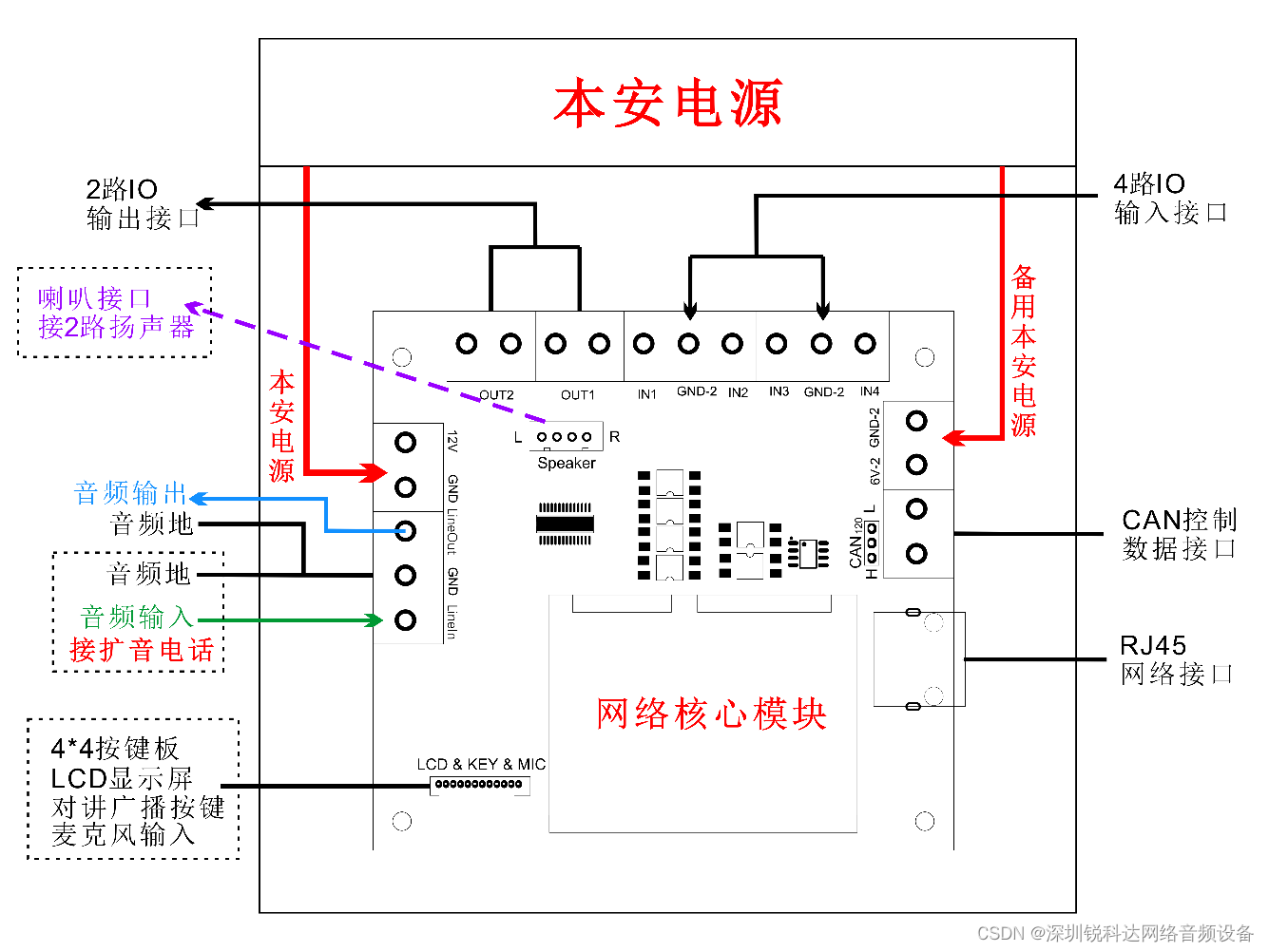
- 干接点输入和输出
4路干接点输入,2路干接点输出,可以通过CAN或者网络与PLC对接
- 4*4键盘及LCD显示器扩展
可以连接标准或者自定义的矩阵键盘
- 低功耗设计
CAN模式下,整机功耗小于5mA,可以适用于电池供电的应用
- 模拟音频输出
可以外接有源号角,实现最大声音的广播喊话
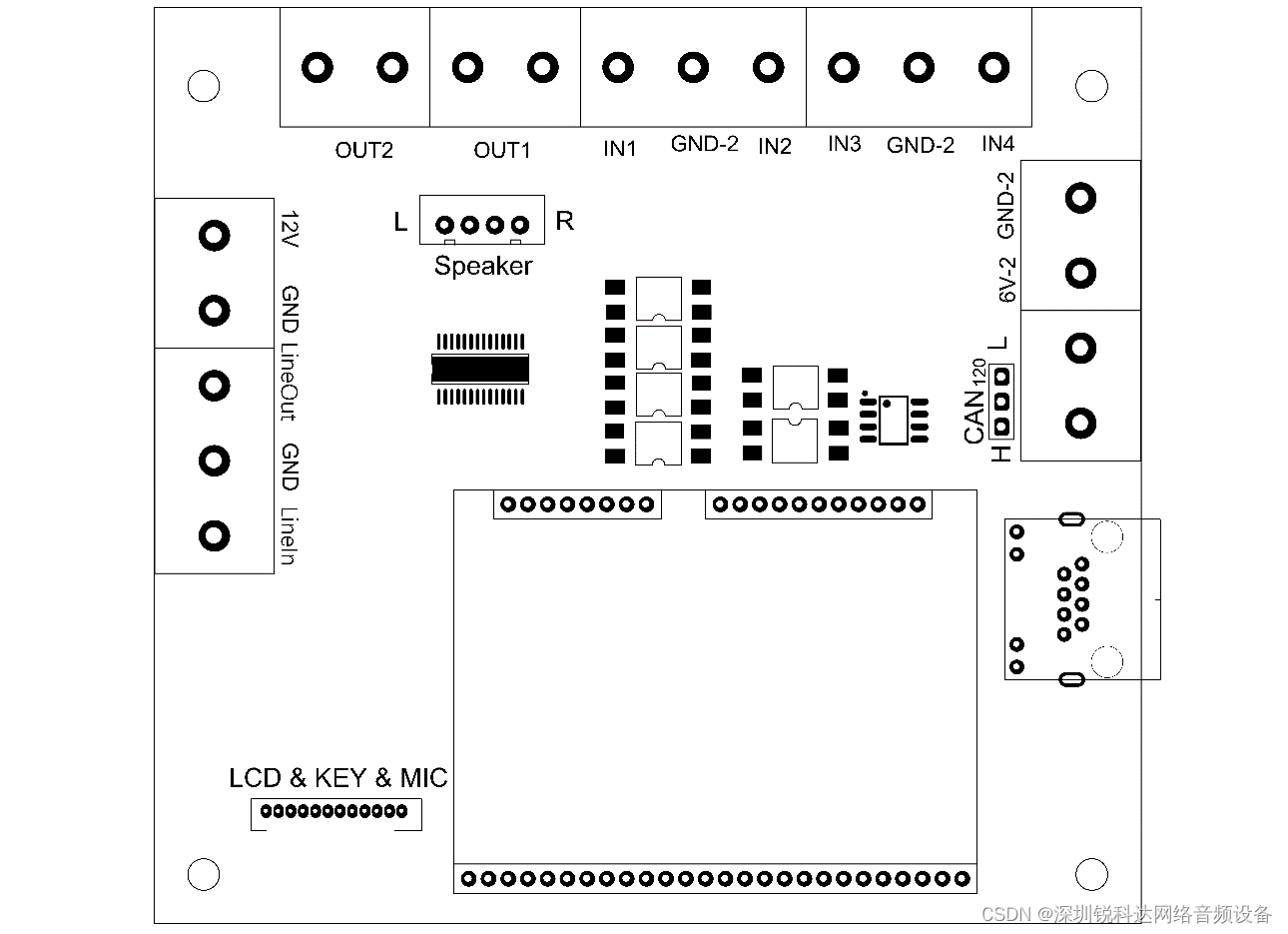
- 电源电路:将本安电源转换为设备需要的几路电源
- 网络模组及网口
- 2*10W功放电路及接口
- Mic输入接口
- 模拟皮带电话电路及接口(2线、峰峰值650mV、阻抗2k,可以考虑增加一路输入输出控制口)
- 模拟号角电路接口(2线、峰峰值650mV、阻抗2k)
- 专用功能按键接口(对讲、广播和打点)
- 4*4键盘LCD显示器接口
- CAN总线接口
- 2路干接点输出接口、4路干接点输入接口
- TF卡电路(备用)
- RS485接口(备用)
四、模块选型
| 型号 | 类型 | 基本功能 | 扩展功能 | CAN数据 | CAN语音 |
| SV-2801VP | 标准型 | SIP对讲、喊话和打点 | |||
| SV-2802VP | 扩展型 | SIP对讲、喊话和打点 | 支持IO | 支持 | |
| SV-2803VP | 全功能 | SIP对讲、喊话和打点 | 支持IO | 支持 | 支持 |
| SV-2801VCP | 标准型 | 支持 | |||
| SV-2802VCP | 扩展能 | 支持IO | 支持 | 支持 |