什么是html5网站软文内容
概念
curl 是一个常用的命令行工具,用于发送各种类型的 HTTP 请求,包括 GET、POST、PUT、DELETE 等。它也可以用来下载文件、上传文件、设置 cookie、发送 multipart/form-data 等等。
使用
调用post接口
实际中的接口:
curl --location --request POST 'http://192.168.11.11:30000/api/science-standard-guide-service/standard-guide/input/submit' \
--header 'Zkrtoken: ccbf61f2ded3dfc3a5df55d676776146c45baeaf3ac647f73fccf8ae2593d09b28fecc779cc75ff4dbf2' \
--header 'Deptid: 2c949aaf837e10ba0183f8c8b5e00186' \
--header 'Positioncode: 01.01.06.08.04' \
--header 'Userid: 2c949aaf837e10ba0183ffe55f4b4c8a' \
--header 'Content-Type: application/json' \
--data-raw '[{"id":"1734377653844185088","standardName": "demoData","standardType": "demoData"}
]'分析
--location:此选项用于启用HTTP重定向的自动处理
--request POST:指定请求方法为POST
--header: 用于设置HTTP头信息
--data-raw: 用于发送原始数据
总的来说,这个命令是向指定的URL发送一个POST请求,并带有多个HTTP头信息和JSON格式的请求体数据
调用get接口
实际中的接口
curl --location --request GET 'http://192.168.15.113:30000/api/science-standard-guide-service/standard-guide/input/detail/1734377653844185088' \
--header 'Zkrtoken: 6a745aec5cfbccbf61f2ded3dfc3a5df55d676776146c45baeaf3ac647f73fccf8ae2593d09b28fecc779cc75ff4dbf2' \
--header 'Deptid: 2c949aaf837e10ba0183f8c8b5e00186' \
--header 'Positioncode: 01.01.06.08.04' \
--header 'Userid: 2c949aaf837e10ba0183ffe55f4b4c8a'
分析
--location:此选项用于启用HTTP重定向的自动处理
--request GET:指定请求方法为GET
--header: 用于设置HTTP头信息
总结:这个命令是向指定的URL发送一个GET请求,用于获取具有特定ID的科学标准指南详情。请求带有多个HTTP头信息,服务器可能会根据这些头信息返回相应的详情数据
在postman中使用curl
将接口curl(bash)从谷歌浏览器复制下来
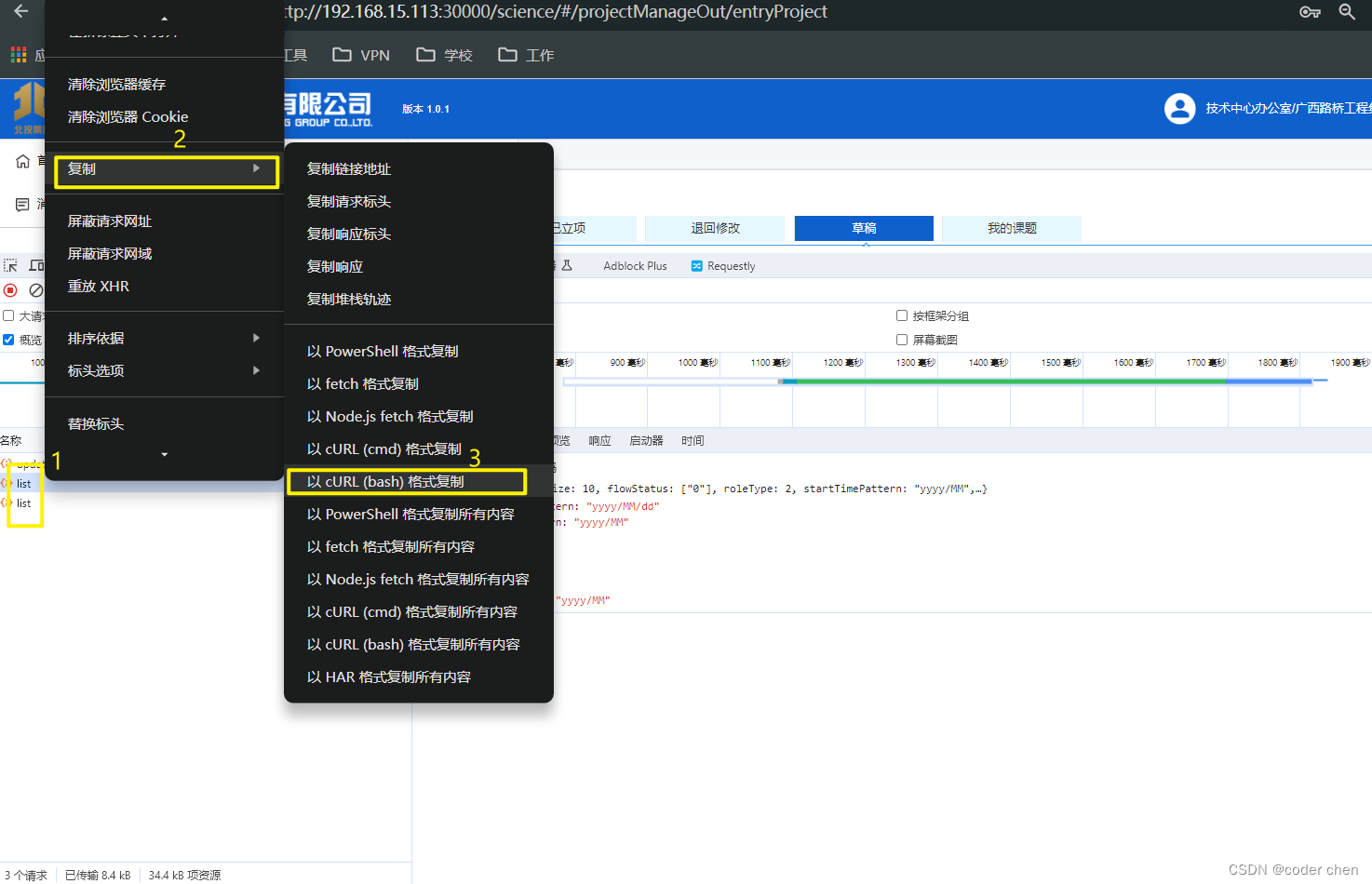
将curl导入postman
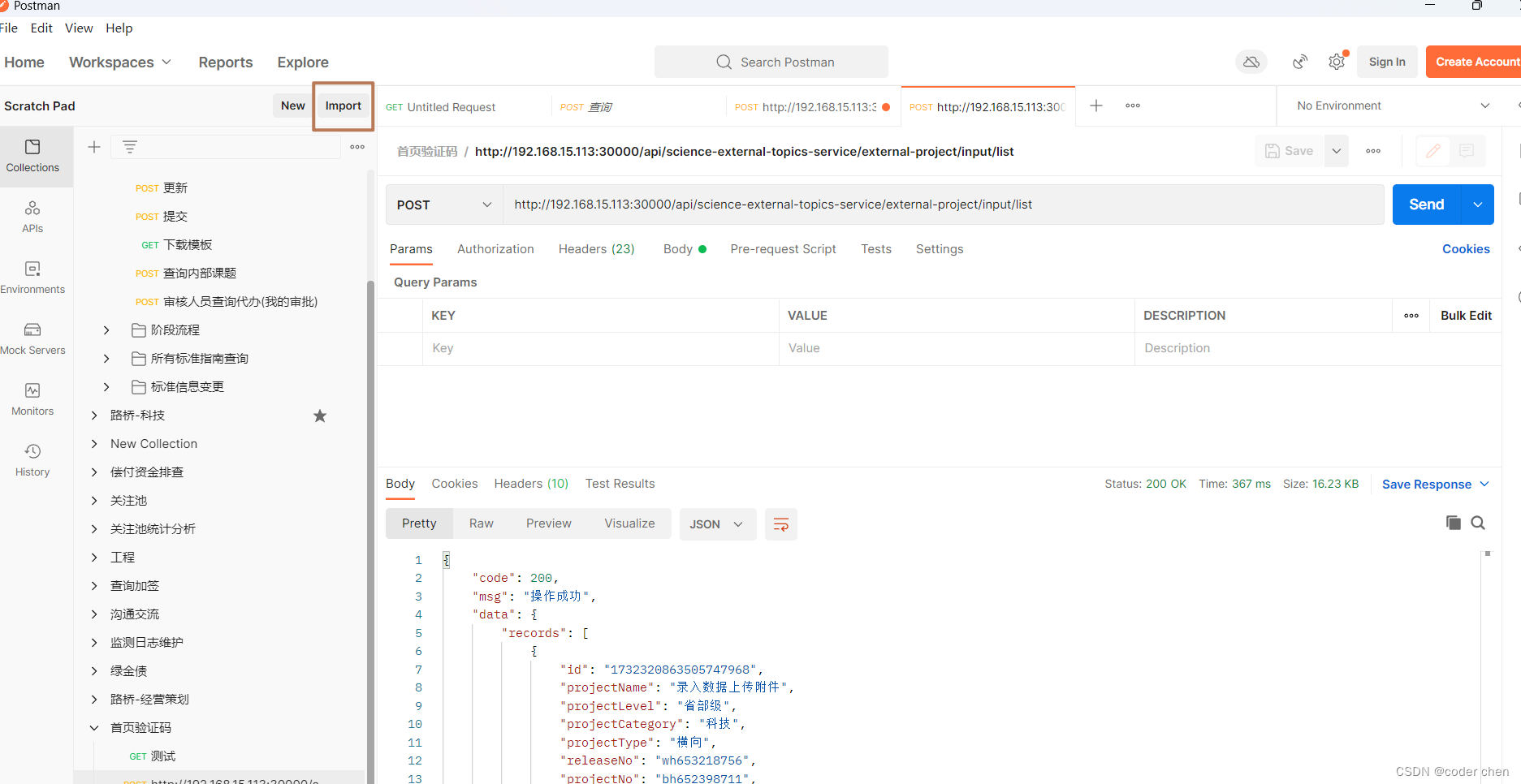
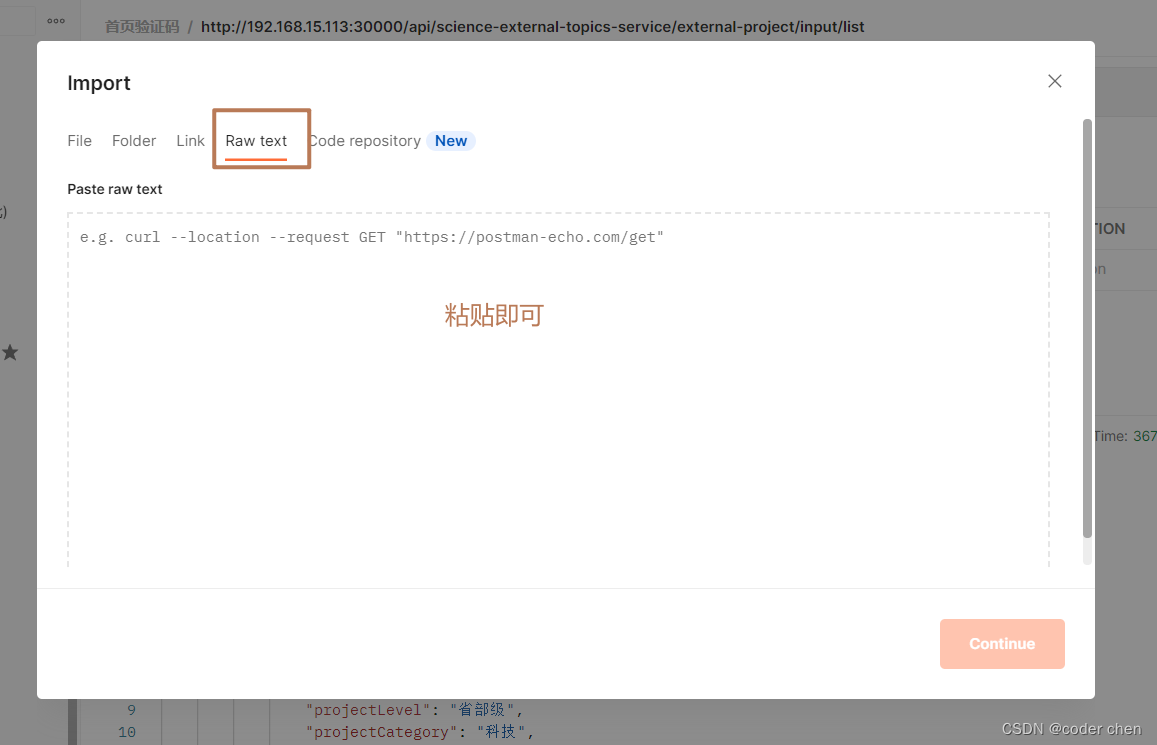
复制进来后相关参数和header头信息就不用自己手动写了,提高开发效率,直接点击发送即可
参考文档:
Postman 导入导出 curl 命令详细步骤 Postman 导入导出 curl 命令详细步骤_postman copy as curl-CSDN博客
一键复制谷歌浏览器请求到Postman:https://www.cnblogs.com/zipxzf/articles/15507026.html
postman 巧用cURL:https://www.cnblogs.com/helloTerry1987/p/11408577.html