怎么做网站的seo星乐seo网站关键词排名优化
前言:
CUDA(Compute Unified Device Architecture,统一计算设备架构)是由NVIDIA公司开发的一种并行计算平台和编程模型。CUDA于2006年发布,旨在通过图形处理器(GPU)解决复杂的计算问题。在早期,GPU主要用于图像处理和游戏渲染,但随着技术的发展,其并行计算能力被广泛应用于科学计算、工程仿真、深度学习等领域。
CUDA的工作原理
CUDA的核心思想是将计算任务分配给GPU上的大量线程,这些线程可以并行地执行任务,从而实现高性能计算。CUDA将GPU划分为多个独立的计算单元,称为“流处理器”(Streaming Processor),这些流处理器可以独立地执行指令,互相加不干扰。
硬件层面
1、CUDA核心 (CUDA Core)
CUDA核心是执行线程计算的基本硬件单元。每个CUDA核心可以执行一个线程的计算任务。
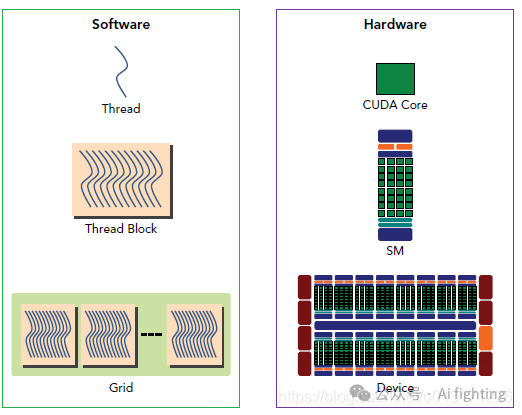
2、SM (Streaming Multiprocessor)
流多处理器 (SM) 是由多个CUDA核心组成的集成单元。每个SM负责管理和执行一个或多个线程块。SM内部有共享内存和缓存,用于加速数据访问和计算。
3、设备 (Device)
设备指的是整个GPU硬件。一个设备包含多个SM,能够处理大量并行计算任务。设备通过高带宽的内存和数据传输机制与主机(如CPU)进行数据交换。
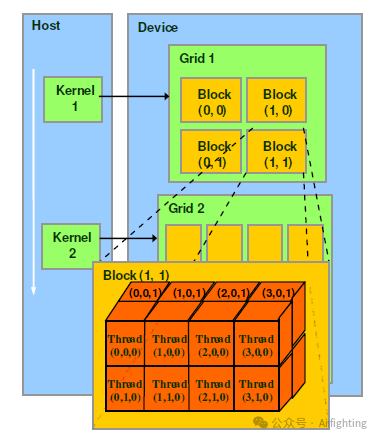
软件层面
1、线程 (Thread)
在CUDA编程中,线程是执行基本计算任务的最小单位。每个线程执行相同的程序代码,但可以处理不同的数据。

2、线程块 (Thread Block)
线程块是由多个线程组成的集合。线程块中的线程可以共享数据,并且可以通过同步机制来协调彼此的工作。线程块的大小在程序执行时是固定的。
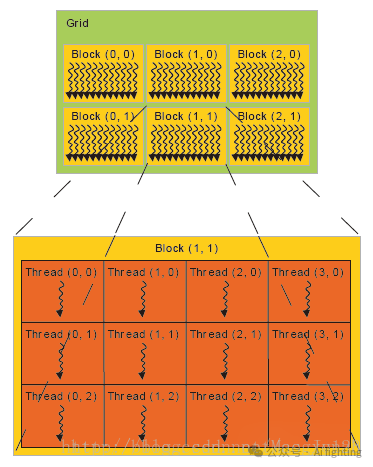
3、网格 (Grid)
网格是由多个线程块组成的更大集合。网格中的所有线程块并行执行任务,网格的大小也在程序执行时固定。

示例
实现两个向量相加 arr_c[] = arr_a[] +arr_b[]
#include <cuda.h>
#include <cuda_runtime_api.h>#include <cmath>
#include <iostream>#define CUDA_CHECK(call) \{ \const cudaError_t error = call; \if (error != cudaSuccess) { \fprintf(stderr, "Error: %s:%d, ", __FILE__, __LINE__); \fprintf(stderr, "code: %d, reason: %s\n", error, \cudaGetErrorString(error)); \exit(1); \} \}__global__ void addKernel(float *pA, float *pB, float *pC, int size)
{int index = blockIdx.x * blockDim.x + threadIdx.x; // 计算当前数组中的索引if (index >= size)return;pC[index] = pA[index] + pB[index];
}int main()
{float a[16] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};float b[16] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};int arr_len = 16;float *dev_a, *dev_b, *dev_c;CUDA_CHECK(cudaMalloc(&dev_a, sizeof(float) * arr_len));CUDA_CHECK(cudaMalloc(&dev_b, sizeof(float) * arr_len));CUDA_CHECK(cudaMalloc(&dev_c, sizeof(float) * arr_len));CUDA_CHECK(cudaMemcpy(dev_a, a, sizeof(float) * arr_len, cudaMemcpyHostToDevice));CUDA_CHECK(cudaMemcpy(dev_b, b, sizeof(float) * arr_len, cudaMemcpyHostToDevice));int *count;CUDA_CHECK(cudaMalloc(&count, sizeof(int)));CUDA_CHECK(cudaMemset(count, 0, sizeof(int)));addKernel<<<arr_len + 512 - 1, 512>>>(dev_a, dev_b, dev_c, arr_len);float *output = (float *)malloc(arr_len * sizeof(float));CUDA_CHECK(cudaMemcpy(output, dev_c, sizeof(float) * arr_len, cudaMemcpyDeviceToHost));std::cout << " output add" << std::endl;for (int i = 0; i < arr_len; i++) {std::cout << " " << output[i];}std::cout << std::endl;return 0;
}代码理解
addKernel<<<arr_len + 512 - 1, 512>>>函数类型如下
addKernel<<<dim3 grid, dim3 block>>>前面的表达等价于
addKernel<<<(dim3 grid(arr_len + 512 - 1), 1, 1), dim3 block(512, 1, 1)>>>grid 与block 理解
假设只使用16个元素, arr_len =16
1、使用调整block的参数:
1.1只有x:
dim3 grid(1, 1, 1), block(arr_len, 1, 1); // 一个block里面有16个线程 // 设置参数
此时遍历的代码如下:
__global__ void addKernel(float *pA, float *pB, float *pC, int size){// block是一维的int index = threadIdx.x; // 计算当前数组中的索引if (index >= size)return;pC[index] = pA[index] + pB[index];}
1.2 含有x, y
dim3 grid(1, 1, 1), block(8, 2, 1); //每个block x方向有8个线程,总共2组。 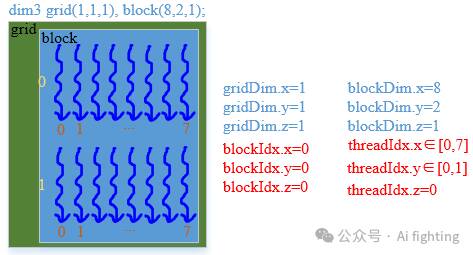
__global__ void addKernel(float *pA, float *pB, float *pC, int size){ // block是二维的int index = threadIdx.x + blockDim.x* threadIdx.y; // 计算当前数组中的索引if (index >= size)return;pC[index] = pA[index] + pB[index];}
2、更改grid 参数
2.1 只更改x方向的参数
dim3 grid(16, 1, 1), block(1, 1, 1); //还有16个block, 每个block就一个线程 // 设置参数
__global__ void addKernel(float *pA, float *pB, float *pC, int size){ // grid.x是一维的int index = blockIdx.x; // 计算当前数组中的索引if (index >= size)return;pC[index] = pA[index] + pB[index];}
3、grid, block参数都改
3.1 grid block各改一个
dim3 grid(4, 1, 1), block(4, 1, 1) // 代码还有4个x方向block, 每个block x方向有4个线程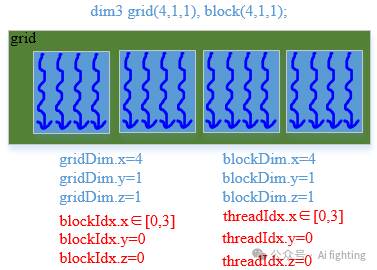
__global__ void addKernel(float *pA, float *pB, float *pC, int size){ // grid.x是一维的int index = blockIdx.x*gridDim.x + threadIdx.x; // 计算当前数组中的索引if (index >= size)return;pC[index] = pA[index] + pB[index];}
3.2 grid block更改两个
dim3 grid(2, 2, 1), block(2, 2, 1) // 代码还有2个X方向block,Y方向上有两组, 每个block x方向有2个线程, y方向上有两组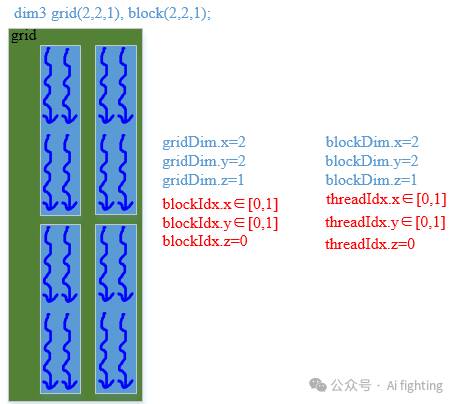
__global__ void addKernel(float *pA, float *pB, float *pC, int size){ // 在第几个块中 * 块的大小 + 块中的x, y维度(几行几列)int index = (blockIdx.y * gridDim.x + blockIdx.x) * (blockDim.x * blockDim.y) + threadIdx.y * blockDim.y + threadIdx.x;if (index >= size)return;pC[index] = pA[index] + pB[index];}
总结
CUDA作为一种强大的并行计算平台和编程模型,极大地推动了高性能计算、深度学习等领域的快速发展。通过掌握CUDA,开发者可以充分利用GPU的并行计算能力,显著提升程序的运行效率和性能。无论是科学研究还是商业应用,CUDA都提供了广阔的可能性和机遇。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。