腾讯建站平台官网网搜网
1、spark概述
spark是专为大规模数据处理而设计的快速通用计算引擎,与Hadoop的MapReduce功能类似,但它是基于内存的分布式计算框架,存储还是采用HDFS。
MapReduce和Spark的区别
- MapReduce的MapReduce之间需要通过磁盘进行数据传递,Spark直接存在内存中,所以速度更快。
- MapReduce的Task调度和启动开销大,而Spark的Task在线程中开销小一些。
- MapReduce编程不够灵活,Spark的API丰富。
- MapReduce的Map和Reduce都要一次shuffle,而Spark可以减少shuffle。
两者框架的区别:
| 功能 | Hadoop组件 | Spark组件 |
|---|---|---|
| 批处理 | MapReduce、Hive或者Pig | Spark Core、Spark SQL |
| 交互式计算 | Impala、presto | Spark SQL |
| 流式计算 | Storm | Spark Streaming |
| 机器学习 | Mahout | Spark ML、Spark MLLib |
Spark具有以下优点:
- 基于内存速度快;
- Java、Python和R语言可以开发spark易用性好;
- spark框架组件丰富,通用性高;
- 可以运行在多种存储结构上,兼容性高。
Spark的缺点:
- 内存消耗大。
2、Spark数据集
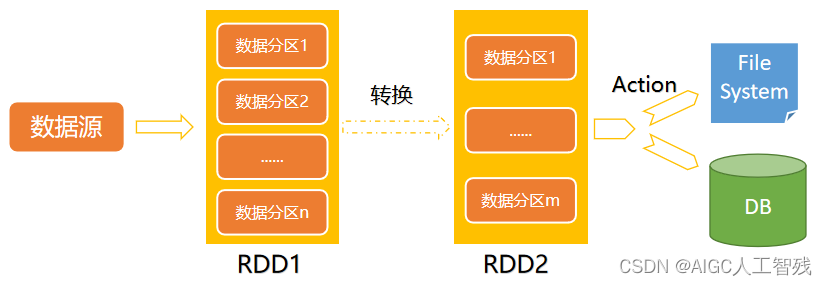
Spark的数据集合采用RDD(Resilient Distributed Dataset)弹性分布式数据集,它是一个不可变、可分区和可并行计算的集合。
- 不可变:RDD1到RDD2时,RDD1任然存在;
- 可分区:可分为多个partition;
- 并行计算;
- Dataset是指数据集,主要用于存放数据;
- Distributed是指分布式存储,并且可以进行分布式计算;
- Resilient弹性的特点:
- 数据可以保存在磁盘中,也可以在内存中;
- 数据分布式存储也是弹性的:
- RDD分在多个节点上存储,与HDFS的分布式存储原理类似:HDFS文件以128M为基准切分为多个block存储在各个节点上,而RDD则会被切分为多个partition,这些partition在不同的节点上;
- spark读取HDFS时,会把HDFS上的block读到内存上对应为partition;
- spark计算结束时,会把数据存储到HDFS上,可以对应到Hive或者HBase上,以HDFS为例:RDD的每一个partition的大小小于128M时,一个partition对应HDFS的block;大于128M时,则会切分为多个block。
3、RDD的数据操作
RDD的数据操作也叫做算子,一共包括三类算子:transformation、action和persist,其中前两种进行数据处理,persist进行数据存储操作。
- transformation:是将一个已经存在的数据集转化为一个新的数据集,map就是一个transformation操作,把数据集的每一个元素传给函数并返回新的RDD
- action:获取数据进行运算后的结果,reduce就是一个action操作,一般聚合RDD所有元素的操作,并返回最终计算结果。
- persist:缓存数据,可以把数据缓存在内存上,也可以缓存在磁盘上,甚至可以到磁盘其他节点上。
我们要了解所有的transformation的操作都是lazy:即不会立刻计算结果,而是记录下数据集的transformation操作,只有调用了action操作之后才会计算所有的transformation,这样会让spark运行效率更高。
pyspark启动
进入SPARK_HOME/sbin⽬录下执⾏
pyspark
sparkUI
可以在spark UI中看到当前的Spark作业 在浏览器访问当前centos的4040端⼝192.168.19.137:4040
启动RDD
3.1 transformation算子
- map(func):将func函数作用到数据集的每一个元素上,返回一个新的RDD
rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
rdd2 = rdd1.map(lambda x:x+1)
print(rdd2.collect())
[2, 3, 4, 5, 6, 7, 8, 9, 10]
- filter(func):筛选func函数中为true的元素,返回一个新的RDD
rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
rdd2 = rdd1.map(lambda x:x*2)
rdd3 = rdd2.filter(lambda x:x>10)
print(rdd3.collect())
[12, 14, 16, 18]
- flatMap(func):先执行map操作,然后将所有对象合并为一个对象
rdd1 = sc.parallelize(["a b c","d e f","h i j"])
rdd2 = rdd1.flatMap(lambda x:x.split(' '))
rdd3 = rdd1.map(lambda x:x.split(' '))
print('flatmap',rdd2.collect())
print('map',rdd3.collect())
flatmap [‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘h’, ‘i’, ‘j’]
map [[‘a’, ‘b’, ‘c’], [‘d’, ‘e’, ‘f’], [‘h’, ‘i’, ‘j’]]
- union(rdd):两个RDD并集
rdd1 = sc.parallelize([("a", 1), ("b", 2)])
rdd2 = sc.parallelize([("c", 1), ("b", 3)])
rdd3 = rdd1.union(rdd2)
print(rdd3.collect())
[(‘a’, 1), (‘b’, 2), (‘c’, 1), (‘b’, 3)]
- intersection(rdd):两个RDD求交集
rdd1 = sc.parallelize([("a", 1), ("b", 2)])
rdd2 = sc.parallelize([("c", 1), ("b", 3)])
rdd3 = rdd1.union(rdd2)
rdd4 = rdd3.intersection(rdd2)
print(rdd4.collect())
[(‘c’, 1), (‘b’, 3)]
- groupByKey():以元祖中的第0个元素为key,进行分组,返回新的RDD,返回的结果中value是Iterable需要list进行转化
rdd1 = sc.parallelize([("a", 1), ("b", 2)])
rdd2 = sc.parallelize([("c", 1), ("b", 3)])
rdd3 = rdd1.union(rdd2)
rdd4 = rdd3.groupByKey()
print(rdd4.collect())
print(list(rdd4.collect()[0][1]))
[(‘b’, <pyspark.resultiterable.ResultIterable object at 0x7f23ab41a4a8>),
(‘c’, <pyspark.resultiterable.ResultIterable object at 0x7f23ab41a4e0>),
(‘a’, <pyspark.resultiterable.ResultIterable object at 0x7f23ab41a438>)]
[2, 3]
- reduceByKey(func):将key相同的键值对,按照func进行计算,返回新的RDD
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd2 = rdd.reduceByKey(lambda x,y:x+y)
print(rdd2.collect())
[(‘a’, 2), (‘b’, 1)]
- sortByKey(ascending=True, numPartitions=None, keyfunc=
tmp2 = [('Mary', 1), ('had', 2), ('a', 3), ('little', 4), ('lamb',5)]
tmp2.extend([('whose', 6), ('fleece', 7), ('was', 8), ('white',9)])
rdd1 = sc.parallelize(tmp2)
rdd2 = rdd1.sortByKey(True,3,keyfunc=lambda k:k.lower())
print(rdd2.collect())
[(‘a’, 3), (‘fleece’, 7), (‘had’, 2), (‘lamb’, 5), (‘little’, 4), (‘Mary’, 1), (‘was’, 8), (‘white’, 9), (‘whose’, 6)]
- mapPatitions(func):分块进行map,默认的map是一行行数据进行,该函数是一块块进行的,适合数据量大的情况。
- sparkContext.broadcast(要共享的数据):当某个数据需要反复查询时,不用把数据放进task中,可以通过⼴播变量, 通知当前worker上所有的task, 来共享这个数据,避免数据的多次复制,可以⼤⼤降低内存的开销。
3.2 action算子
- collect():返回⼀个list,list中包含 RDD中的所有元素,建议数量较小时使用,数据较大不会全部显示
rdd1 = sc.parallelize([1,2,3,4,5])
print(rdd1.collect())
[1, 2, 3, 4, 5]
- reduce(func):将RDD中元素两两传递给输⼊函数,同时产⽣⼀个新的值,新产⽣的值与RDD中下⼀个元素再被传递给输⼊函数直到最后只有⼀个值为⽌。
rdd1 = sc.parallelize([1,2,3,4,5])
result = rdd1.reduce(lambda x,y:x+y)
print(result)
15
- first():返回RDD中的第一个元素
rdd1 = sc.parallelize([1,2,3,4,5])
result = rdd1.first()
print(result)
1
- take(num):返回RDD的前num个元素
rdd1 = sc.parallelize([1,2,3,4,5])
result = rdd1.take(3)
print(result)
[1, 2, 3]
- count():返回RDD元素个数
rdd1 = sc.parallelize([1,2,3,4,5])
result = rdd1.count()
print(result)
5
4、Spark架构
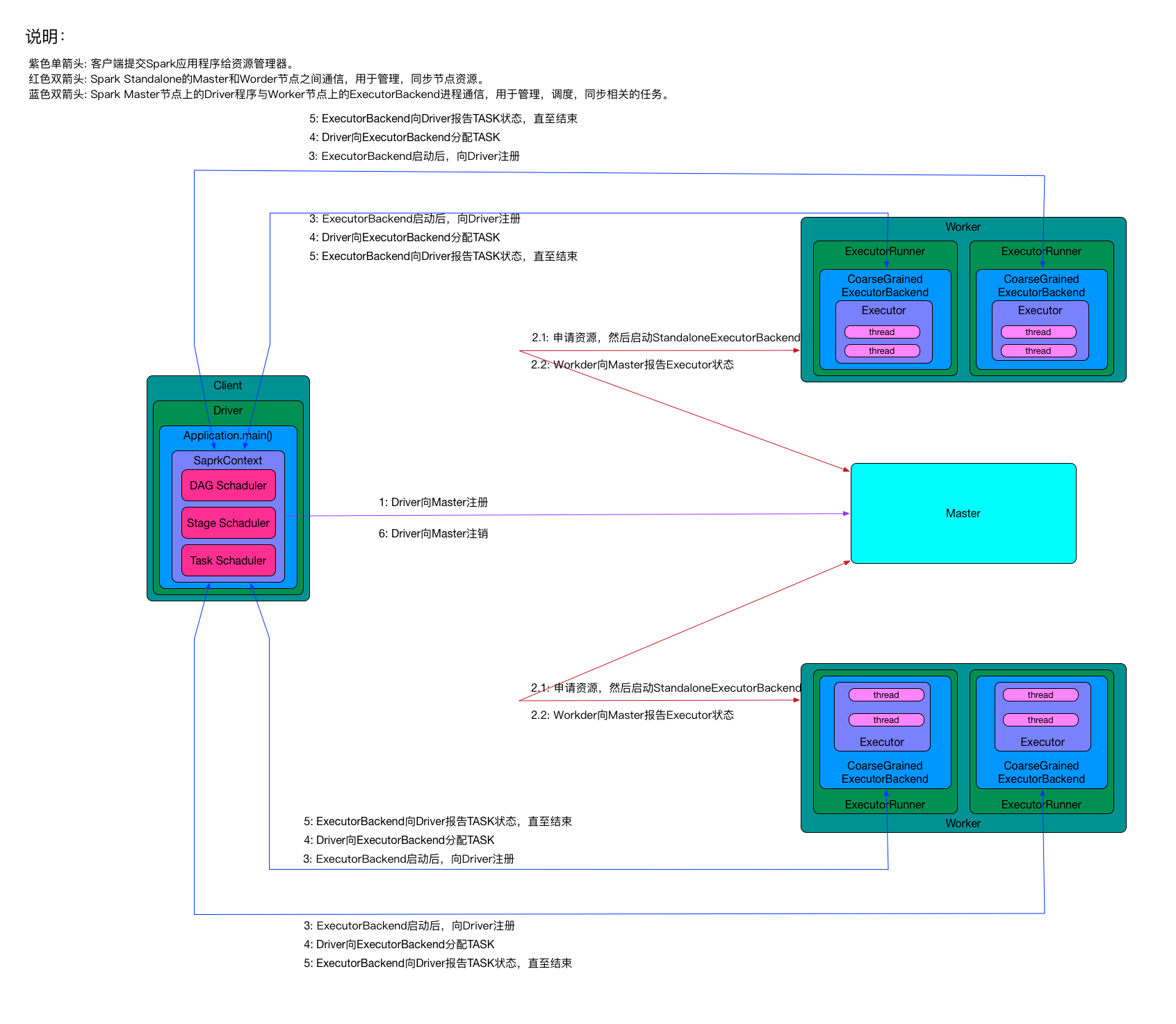
- Client:客户端进程
- Driver:一个Spark作业负责一个Driver进程,负责向Master注册和注销,包括:StageScheduler、TaskSchedule和DAGSchedule。
- StageSchedule:负责生成Stage。
- Stage:一个Spark作业一般包含一到多个Stage。
- DAGSchedule:负责将Spark作业分解成一个多个Stage,将Stage根据RDD的Partition个数决定Task个数,然后放到TaskSchedule中。
- TaskSchedule:将Task分配到ExecutorBackend上执行,并监控Task状态。
- Task:一个Stage包含一个多个Task,多个Task实现并行运行。
- StageSchedule:负责生成Stage。
- Application:Spark应用程序,批处理作业的集合。其中main方法时入口,定义了RDD和RDD的操作。
- Master:Standalone模式中的主控节点,负责接收Client提交的作业,管理Worker,并让Worker启动Driver和Executro。
- Worker:Standalone模式中的salve节点上的守护节点,负责管理本节点的资源,定期向Master汇报心跳,接收Master命令,启动Driver和Executor。
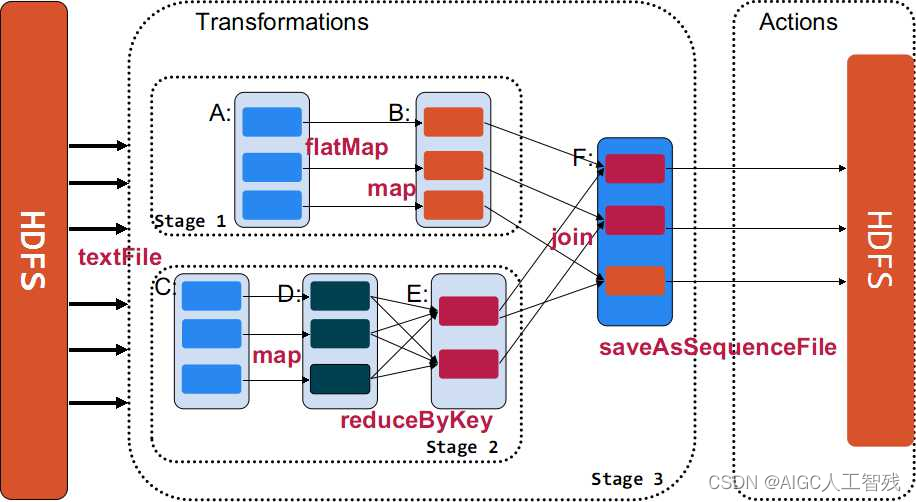
Spark作业的Stage划分
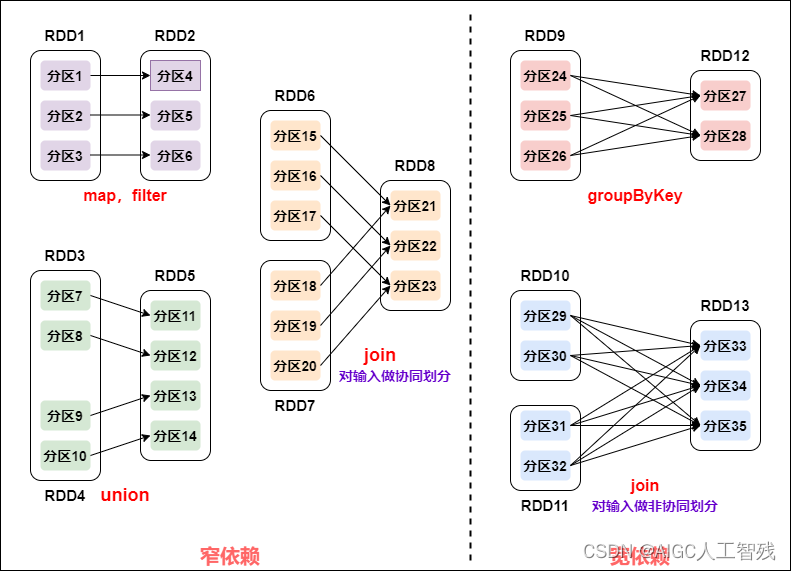
- 窄依赖:父RDD的每个Partition最多被一个子RDD的Partition所使用,即一个父RDD对应一个子RDD。map、filter、union、join对输入做协同划分。
- 宽依赖:子RDD依赖所有父RDD分区。groupByKey、join对输入做非协同划分。
窄依赖的所有RDD作为一个Stage,遇到宽依赖结束。