开鲁企业网站建设十大品牌营销策划公司
目录
- 总纲
- redis的k,v键值对
- 新的三大类型
- 五种经典数据类型
- redisObject
- 结构图示
- 结构讲解
- 数据类型与数据结构关系图示
- string数据类型
- 三大编码格式
- SDS详解
- 代码结构
- 为什么要重新设计
- 源码解析
- 三大编码格式
- hash数据类型
- ziplist和hashtable编码格式
- ziplist详解
- 结构剖析
- ziplist的优势(为什么要在设计一个结构出来)
- zlentry详解
- OBJ_ENCODING_HT详解
- list数据类型
- quicklist编码格式
- 压缩配置项
- list-compress-depth
- list-max-ziplist-size
- set数据类型
- set-max-intset-entries
- zset数据类型
- skiplist(跳跃表)
- 复杂度
- 优缺点
- 最终总结
- 结构表
- 结构图示
- 时间复杂度
- 文字描述
总纲
redis的k,v键值对
redis是key-value存储系统,其中key类型一般为字符串,value类型为redis对象(redisObject)
redis定义了redisObject结构体,来表示string,hash,list,set,zset等数据类型
每个键值对都会有一个dictEntry

新的三大类型
- bitmap: 本质是string
- hyperLogLog: 本质是string
- GEO: 本质是Zset
五种经典数据类型
redisObject
为了便于操作,redis采用了redisObject结构来统一五种不同的数据类型,这样所有的数据类型就都可以以相同的形式在函数间传递而不使用特定的类型结构.同时,为了识别不同的数据类型,redisObject中定义了type和encoding字段对不同的数据类型加以区分.简单的讲,redisObject就是stirng,hash,list,set,zset的父类,可以在函数间传递时隐藏具体的类型信息,所以作者把他抽象出来.
结构图示

结构讲解
- type:4 指的是当前值对象的数据类型
- encoding:4 指的是当前值对象底层存储的编码类型
- lru:LRU_BITS 采用lru算法清除内存中的对象
- int refcount 记录对象引用次数
- void *ptr 指向真正的底层数据结构的指针
数据类型与数据结构关系图示

string数据类型
三大编码格式
| 格式 | 解释 | 补充说明 |
|---|---|---|
| int | 保存long型(长整型)的64位(8个字节)有符号整数 | 只有整数才会使用int,如果是浮点数,Redis内部会转为字符串值在保存,如果是整数,超过long的最大值的话就会转变为embstr类型 |
| embstr | SDS(Simple Dynamic String简单动态字符串),保存长度小于44字节的字符串 | 长度大于44字节就会转变为raw类型 |
| raw | 保存长度大于44字节的字符串 |
SDS详解
Redis没有直接复用C语言的字符串,而是新建了属于自己的结构----SDS.在Redis数据库里,包含字符串的键值对都是由SDS实现的(Redis中所有的键都是由字符串对象实现的,即底层是由SDS实现,Redis中所有的值对象中包含的字符串对象底层也是由SDS实现)
代码结构
struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; /* 当前字符数组的长度 */uint8_t alloc; /* 当前字符数组总共分配的内存大小 */unsigned char flags; /* 当前字符串数组的属性,用来标识是sdshdr8还是sdshdr16等等 */char buf[]; /* 字符串真正的值 */
};
struct __attribute__ ((__packed__)) sdshdr16 {uint16_t len; /* used */uint16_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {uint32_t len; /* used */uint32_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {uint64_t len; /* used */uint64_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];
};
有多个定义,数值越高,存储的字符数组越大
为什么要重新设计
| C语言 | SDS | |
|---|---|---|
| 字符串长度处理 | 需要从头遍历,一直到遇到\0为止,时间复杂度为O(N) | 直接记录当前字符串长度,直接读取,时间复杂度为O(1) |
| 内存重新分配 | 分配内存空间超过后,会导致数组下标越级或者内存分配溢出 | 空间预分配:sds修改以后len长度小于1M,那么将会分配与len长度相同的未使用空间,如果修改后大于1m,那么将分配1m的使用空间 惰性空间释放:sds缩短不会回收内存,而是用free记录多余的空间,后续变更直接使用free记录的空间,减少内存的分配次数 |
| 二进制安全 | 二进制数据不是规则的字符串格式,可能会包含特殊字符,比如 \0等,此时C语言就会读取结束 | 根据len长度来判断字符串结束的,二进制的安全问题就得以解决了 |
源码解析
Redis启动时会预先建立10000个分别是0-9999的redisObject变量作为共享对象,这就意味着如果set字符串的键值在0-9999之间的话,则可以直接指向共享对象而不需要在建立新对象,此时键值不占空间
三大编码格式
redis的Object.c源代码的tryObjectEncoding方法
/* Try to encode a string object in order to save space */
robj *tryObjectEncoding(robj *o) {long value;sds s = o->ptr;size_t len;serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);if (!sdsEncodedObject(o)) return o;if (o->refcount > 1) return o;len = sdslen(s);if (len <= 20 && string2l(s,len,&value)) {//字符串如果小于等于20且字符串转long型成功if ((server.maxmemory == 0 ||!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&value >= 0 &&value < OBJ_SHARED_INTEGERS){//配置maxmemory且值在10000以内.直接使用共享对象的值decrRefCount(o);incrRefCount(shared.integers[value]);return shared.integers[value];} else {if (o->encoding == OBJ_ENCODING_RAW) {sdsfree(o->ptr);o->encoding = OBJ_ENCODING_INT;o->ptr = (void*) value;return o;} else if (o->encoding == OBJ_ENCODING_EMBSTR) {decrRefCount(o);return createStringObjectFromLongLongForValue(value);}}}//如果长度小于embstr的长度,就转为embstr// 作者定义长度为44字节 #define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44//embstr的含义就是嵌入式的string,从内存上讲就是字符串的sds结构体与其对应的redisObject对象//分配在同一块连续的内存空间if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {robj *emb;if (o->encoding == OBJ_ENCODING_EMBSTR) return o;emb = createEmbeddedStringObject(s,sdslen(s));decrRefCount(o);return emb;}//大于44的直接就是raw对象trimStringObjectIfNeeded(o);/* 返回最终的对象 */return o;
}
对于embstr,由于其实现是只读的,因此在对embstr修改时,都会先转化为raw再进行修改,因此,只要是修改embstr对象,修改后的对> > 象一定是raw的,无论是否达到了44个字节
redis内部会根据用户给的不同键值而使用不同的编码格式,自适应的选择较优的内部编码格式,而这一切对用户完全透明
hash数据类型
ziplist和hashtable编码格式
| 参数名称 | 参数解释 | 默认值 |
|---|---|---|
| hash-max-ziplist-entries | 使用压缩列表保存时哈希集合中的最大元素个数 | 哈希对象保存的键值对数量小于512个 |
| hash-max-ziplist-value | 使用压缩列表保存时哈希集合中单个元素的最大长度 | 所有的键值对的键和值的字符串长度都小于等于64byte(一个英文字母一个字节)时用ziplist,反之用hashtable |
hash类型键的字段数小于hash-max-ziplist-entries并且每个字段名和字段值的长度小于hash-max-ziplist-value的时候,redis才会使用OBJ_ENCODING_ZIPLIST(ziplist)来存储,前述的条件任意一个不满足就会转变为OBJ_ENCODING_HT(hashtable)的编码格式
ziplist升级到hashtable可以,但是他不会在进行降级
ziplist详解
ziplist是一种紧凑的编码格式,总体思想是多花时间来换取节约空间,即以部分读写性能为代价,来换取极高的内存空间利用率.因此只会用于字段个数少,且字段值也比较小的场景,压缩列表内存利用率极高的原因与其连续内存的热醒是分不开的
embstr也是嵌入式string,内存与redisObject是连续不分开的,redis在这方面特别重视(因为他主要就是玩内存的,他想去尽量的减少内存碎片)
结构剖析
ziplist是一个经过特殊编码的双向链表,不过他并不存储指向上一个节点和下一个节点的指针,而是去存储上一个节点长度和当前节点的长度.
结构图示:
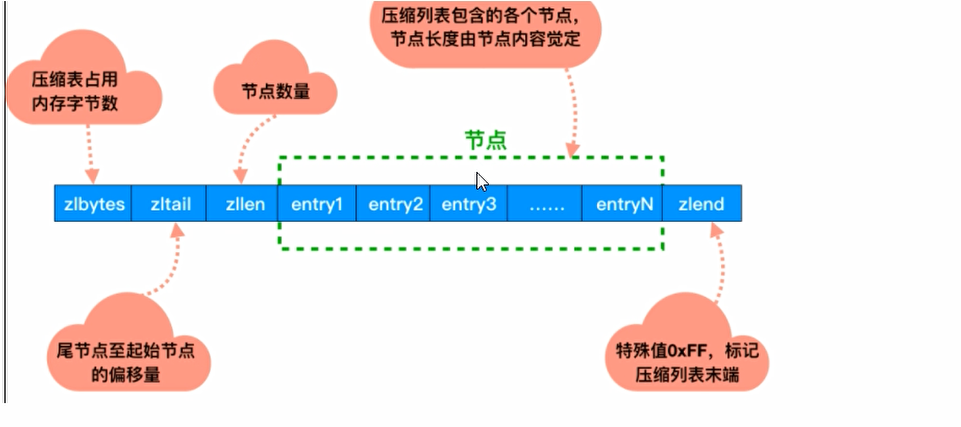
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配,或者计算zlend的位置时使用 |
| zltail | uint32_t | 4字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,程序无须遍历整个压缩列表就可以确定表尾节点的地址 |
| zllen | uint16_t | 2字节 | 记录了压缩列表包含的节点数量:当这个属性的值小于UINT16_MAX(65536)时,这个属性的值就是压缩列表包含节点的数量;当这个值等于UINT16_MAX时,节点的真实数量需要遍历整个压缩列表才能计算得出 |
| entryX | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定 |
| zlend | uint8_t | 1字节 | 特殊值0xFF(二进制八个1),用于标记压缩列表的末端 |
ziplist的优势(为什么要在设计一个结构出来)
- 普通的双向链表会有两个指针,在存储数据很小的情况下,我们存储的实际数据大小很可能还没有指针占用的内存大,得不偿失.所以ziplist没用指针,而是改为维护上一个和当前entry的长度,通过长度推算下一个元素在什么位置,牺牲读取的性能来获得最高效的存储空间,是典型的的时间换空间的思想.
- 键表在内存中一般都是不连续的(因为可以靠指针,不用考虑连续的问题),遍历相对较慢,而ziplist正好解决了这个问题,他是内存上要求必须连续的,但是由于他每个节点的长度可以不相等,所以遍历的时候需要记录长度信息作为偏移量用来遍历整个链表.使之能够跳到上一个节点或者是下一个节点
- 头节点里同时还存在一个参数len.和string类型的sds相似,这里是用来记录链表长度的,因此获取链表长度时不用再遍历整个链表,直接拿到len值就可以了,时间复杂度为O(1)
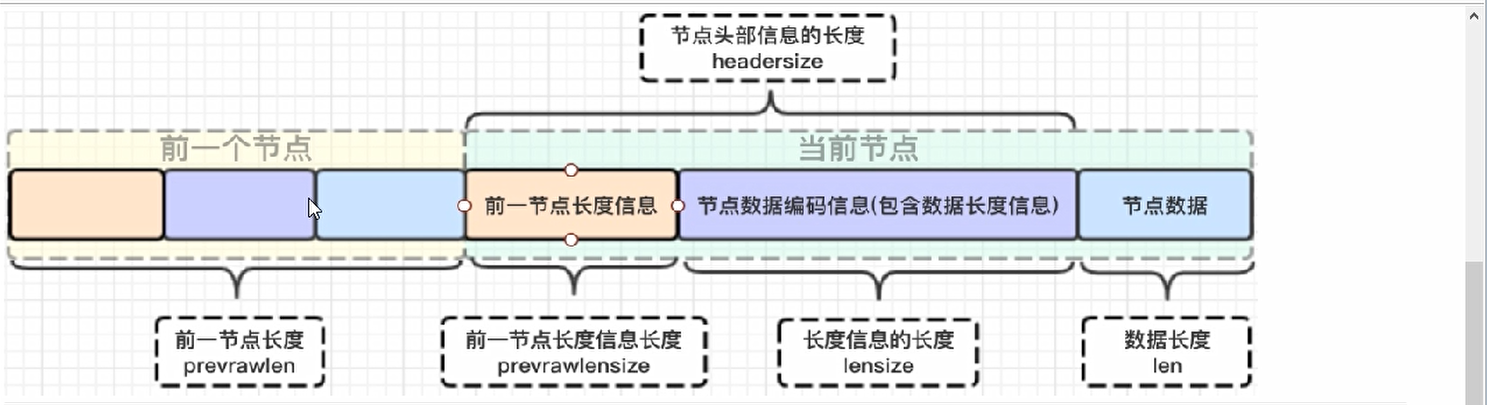
zlentry详解
entry的代码结构:
//压缩链表节点结构
typedef struct zlentry {unsigned int prevrawlensize; /* 存储上一个链表节点的长度数值所需要的字节数(1字节或者5字节,为了对齐填充) */unsigned int prevrawlen; /* 上一个链表节点占用的长度 */unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数*/unsigned int len; /* 当前链表节点占用的长度 */unsigned int headersize; /* 当前链表节点的头部大小(prevrawlensize+lensize),即非数据域大小 */unsigned char encoding; /* 编码方式 */unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
} zlentry;

OBJ_ENCODING_HT详解
OBJ_ENCODING_HT这种编码方式内部才是真正的哈希表结构,可以实现O(1)级别的读写操作,在Redis内部,从OBJ_ENCODING_HT类型到底层真正的散列表数据结构是一层层的嵌套下去的,如图所示:

list数据类型
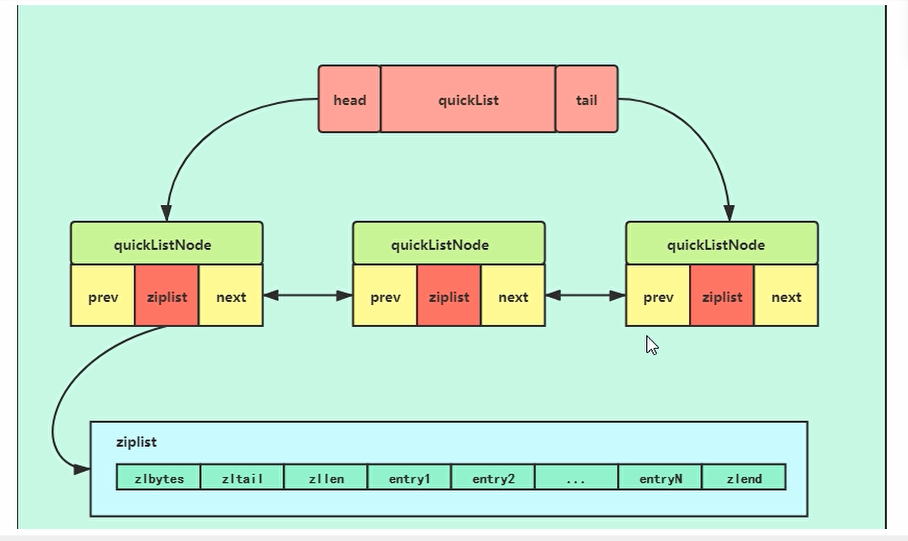
quicklist编码格式
在redis里面,list用quicklist来存储,quicklist存储了一个双向链表,每个节点都是一个ziplist,他是ziplist加上linkedlist的结合体
图示:

压缩配置项
list-compress-depth
表示一个quicklist两端不被压缩的节点个数,这里的节点是quicklist双向链表的节点,含义如下
- 0:是个特殊值,表示都不压缩,这是Redis的默认值
- 1:表示quicklist两端各有一个节点不压缩,中间的节点压缩
- 2:表示quicklist两端各有两个节点不压缩,中间的节点压缩
- 3:表示quicklist两端各有三个节点不压缩,中间的节点压缩
依次类推下去…
list-max-ziplist-size
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度.比如当这个数据项设置为5的时候,表示每个quicklist节点的ziplist最多包含五个数据项.当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度.这时,他只能取-1到-5这五个值
- -5: 每个quicklist节点上的ziplist大小不能超过64KB
- -4: 每个quicklist节点上的ziplist大小不能超过32KB
- -3: 每个quicklist节点上的ziplist大小不能超过16KB
- -2: 每个quicklist节点上的ziplist大小不能超过8KB(-2也是Redis给的默认值)
- -1: 每个quicklist节点上的ziplist大小不能超过4KB
set数据类型
Redis用inset和hashtable两种编码格式来存储set,如果元素都是整数类型并且个数小于512个,就用intset存储,如果不是整数类型,就用hashtable(数组加链表的存储结构).key就是元素的值,value为null
set-max-intset-entries
默认值为512,配置整型set的元素最大个数,超过的话就会变为hashtable
zset数据类型
当有序集合中包含的元素数量超过服务器属性server.zset_max_ziplist_entries的值(默认值是128),或者有序集合中新添加元素的member的长度大于服务器属性server.zset_max_ziplist_value的值(默认值为64)时,redis会使用跳跃表作为有序集合的底层实现。否则会使用ziplist作为有序列表的底层实现。
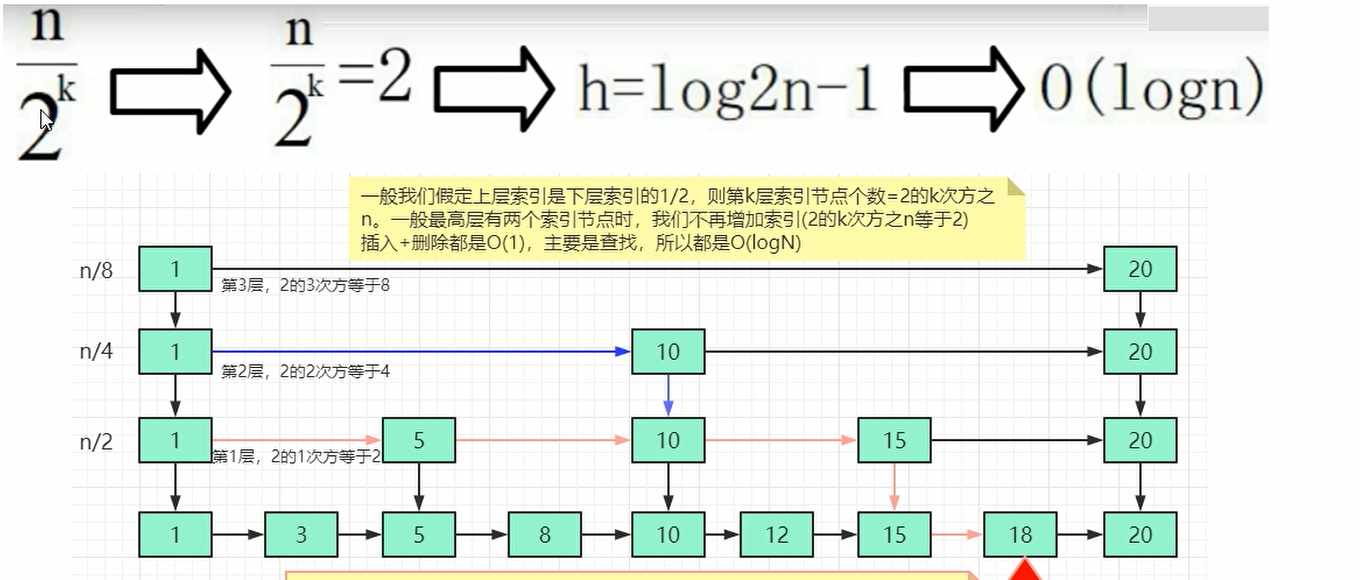
skiplist(跳跃表)
跳表是可以实现二分查找的有序链表.他是一种以空间换取时间的结构,由于链表无法进行二分查找,因此借鉴数据库的索引思想,提取出链表中关键节点(索引),先在关键节点上查找,在进入下层的链表查找,提取多层关键节点,就形成了二分查找的跳跃表结构.
总结来说跳表 = 链表 + 多级索引(两两取首升级为索引,一级一级进行嵌套)
复杂度
时间复杂度为O(logN),空间复杂度为O(n),新增修改删除的时间复杂度也是O(logN)
优缺点
典型的空间换时间的策略,而且只有在数据量大的时候才能体现出来优势,比较适应读多写少的场景,所以使用范围比较有限,这里需要注意,数据量大的同时写太多的话可能会一直需要调整各级别的索引,所以会耗时较多
最终总结
结构表
| 类型 | 编码 | 对象 |
|---|---|---|
| REDIS_STRING | REDIS_ENCODING_INT | 使用整数值实现的字符串对象 |
| REDIS_STRING | REDIS_ENCODING_EMBSTR | 使用embstr编码的简单动态字符串实现的嵌入式字符串对象 |
| REDIS_STRING | REDIS_EMCODING_RAW | 使用简单动态字符串实现的字符串 |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST | 使用压缩列表ziplist实现的列表对象 |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST | 使用双端链表quicklist实现的列表对象 |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST | 使用压缩列表ziplist实现的哈希对象 |
| REDIS_HASH | REDIS_ENCODING_HT | 使用字典hashtable实现的哈希对象 |
| REDIS_SET | REDIS_ENCODING_INSET | 使用整数集合实现的集合对象 |
| REDIS_SET | REDIS_ENCODING_HT | 使用字典实现的集合对象 |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的有序集合对象 |
| REDIS_ZSET | REDIS_ENCODING_SKIPLIST | 使用跳跃表和字典实现的有序集合对象 |
结构图示

时间复杂度
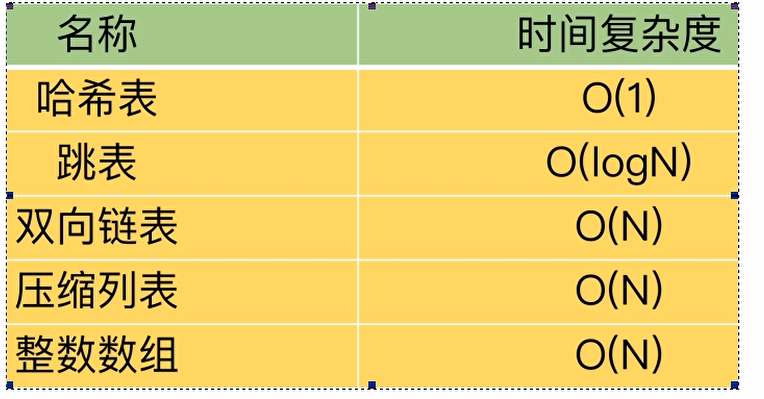
文字描述
- string字符串(redis会根据当前值的类型和大小决定使用哪种内部编码实现)
- int:8个字节的长整型
- embstr:小于等于44个字节的嵌入式字符串(内存地址与redisObject连续)
- raw:大于44个字节的字符串
- hash哈希
- ziplist(压缩列表):当哈希元素个数小于hash-max-ziplist-entries配置(默认512个),同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会采用ziplist作为哈希的内部实现,ziplist内存更加的紧凑和节省,所以节约内存方面比起来hashtable要优秀
- hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis就会改用hashtable作为哈希的内部实现,因为此时的ziplist的读写效率下降,而hashtable的读写复杂度为O(1)
- list列表
- ziplist:当列表的元素个数小于list-max-ziplist-entries配置(默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置(默认是64个字节)时.Redis会采用ziplist来作为列表的内部实现来减少内存的使用
- linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会采用quicklist作为内部实现.quick是linkedlist和ziplist的结合,以ziplist为节点的链表(linkedlist)
- set集合
- inset(整数集合):当集合中的元素都是整数且元素个数小于set-max-inset-entries配置(默认512个)时,Redis会采用inset来作为集合的内部实现,从而减少内存的使用
- hashtable:当集合类型无法满足inset时,Redis会采用hashtable作为内部实现
- zset有序集合
- ziplist:当有序集合的元素个数小于zset-max-ziplist-entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,Redis会采用ziplist来作为有序集合的内部实现,ziplist可以有效减少内存的使用
- skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时ziplist的读写效率会下降
感觉这些多种编码数据结构实现的设计就是在时间和空间上寻求一种平衡,毕竟redis追求的是极致的性能,他就是从这些小细节的架构上体现出来的高性能的标杆