宸建设计网站小说推广关键词怎么弄
有时 Logstash Grok 没有我们需要的模式。 幸运的是我们有正则表达式库:Oniguruma。在很多时候,如果 Logstash 所提供的正则表达不能满足我们的需求,我们选用定制自己的表达式。
定义
- Logstash 是一种服务器端数据处理管道,可同时从多个来源获取数据,对其进行转换,然后将其发送到 “存储”(如 Elasticsearch)。
- Grok 是 Logstash 中的过滤器,用于将非结构化数据解析为结构化和可查询的内容。
- Regular expression 是定义搜索模式的字符序列。
如果你已经在运行 Logstash,则无需安装额外的正则表达式库,因为 Grok 位于正则表达式之上,因此任何正则表达式在 grok 中也有效 —— Elastic 文档。
语法
Grok
Grok 语法如下:
%{SYNTAX:SEMANTIC}- SYNTAX 是默认的 grok 模式
- SEMANTIC 是 key
Oniguruma
oniguruma 语法如下:
(?<field_name>the pattern here)Grok + Oniguruma
你可以像下面这样组合 Grok 和 Oniguruma:
%{SYNTAX:SEMANTIC} (?<field_name>the pattern here)让我们开始吧
样本数据
为了演示我们如何将 Oniguruma 与 Grok 结合使用,我们将在示例中使用下面的日志数据。
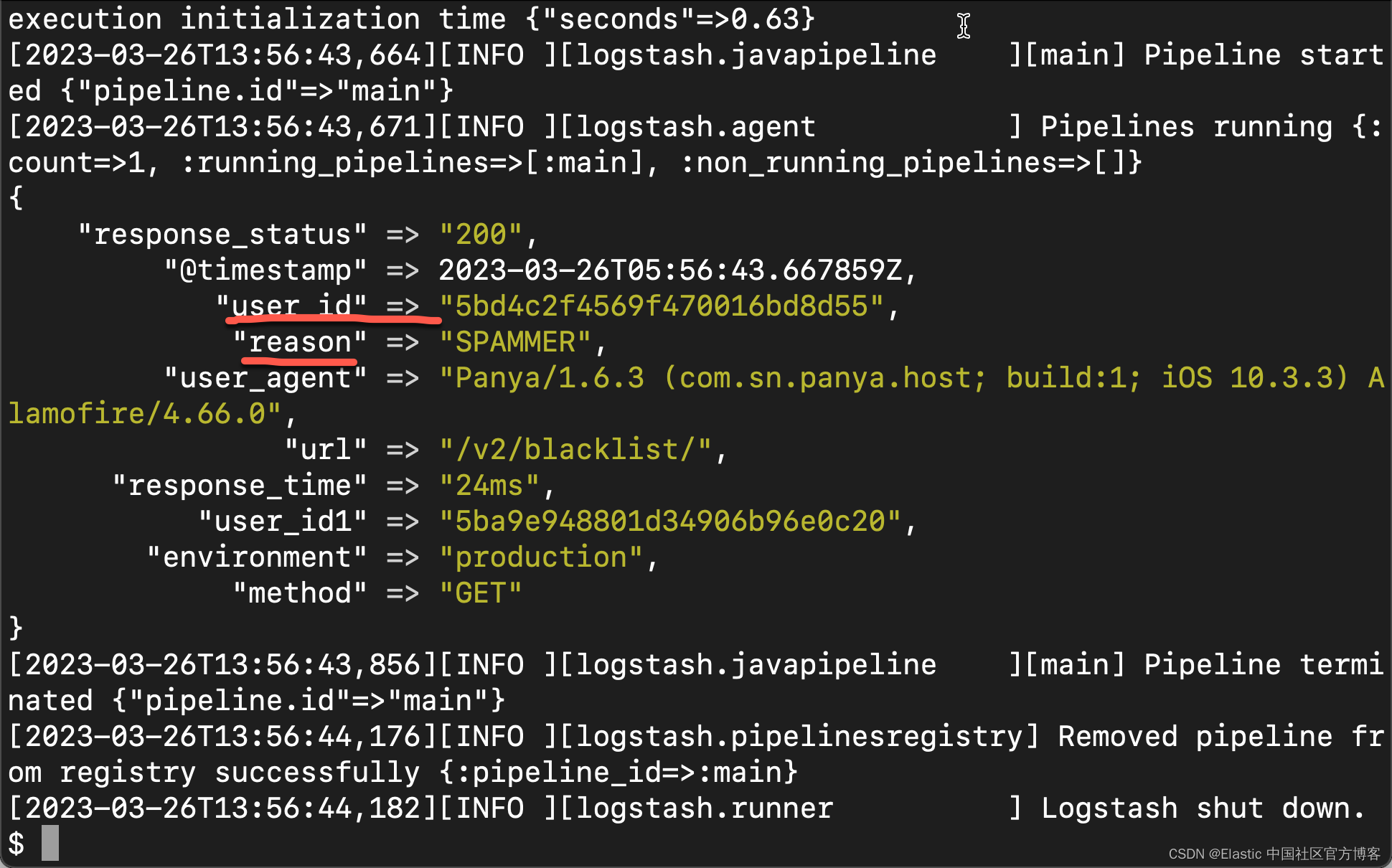
production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 {\"user_id\":\"5bd4c2f4569f470016bd8d55\",\"reason\":\"SPAMMER\"}
日志数据结构:
production == environment
GET == method
/v2/blacklist == url
200 == response_status
24ms == response_time
5bc6e716b5d6cb35fc9687c0 == user_id
Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 == user_agent
{\"user_id\":\"5bd4c2f4569f470016bd8d55\",\"reason\":\"SPAMMER\"} == req.body目的:
目标是找到一种模式来构造非结构化日志数据。为此,我们将使用 Kibana 里的 Grok Debugger 来进行测试:
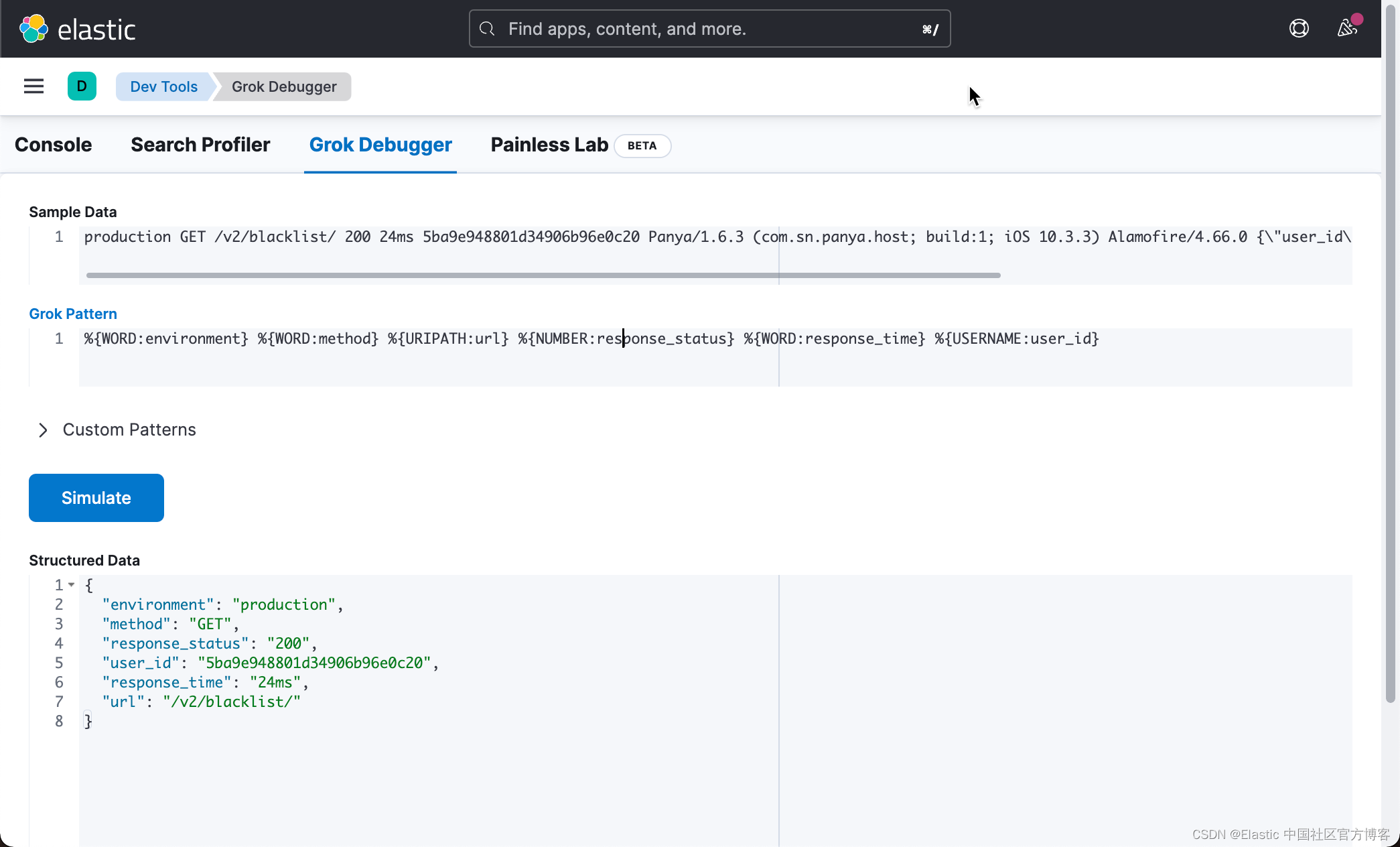
其中,我们的 Grok pattern 定义如下:
%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}如上所示,上面的 Grok pattern 产生如下的结果:
{"environment": "production","method": "GET","response_status": "200","user_id": "5ba9e948801d34906b96e0c20","response_time": "24ms","url": "/v2/blacklist/"
}这是一个不错的开始,但还不完整。 没有 user_agent 和 req.body 的映射。要提取 user_agent 和 req.body,我们需要仔细检查其结构。
空格分隔符
值 production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 由空格分隔,这很容易使用。
但是,对于 user_agent,可以有动态数量的空格,具体取决于发送请求的硬件类型。
Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 我们如何解释这种持续变化?
提示:看一下 req.body 的结构。
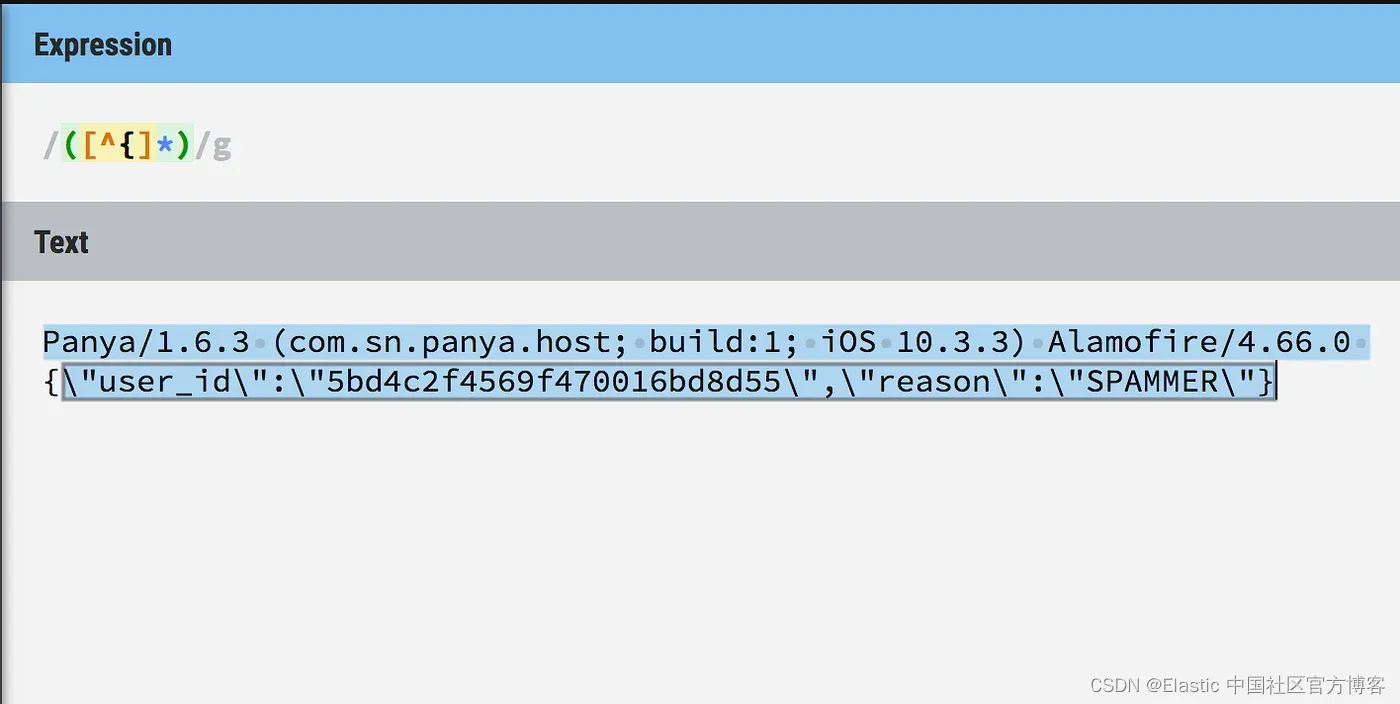
{\”user_id\”:\”5bd4c2f4569f470016bd8d55\”,\”reason\”:\”SPAMMER\”}我们可以看到 req.body 是由花括号 {} 组成的。
利用这些知识,我们可以构建一个自定义正则表达式模式来查找第一个左括号之前的所有内容,然后获取之后的所有内容。
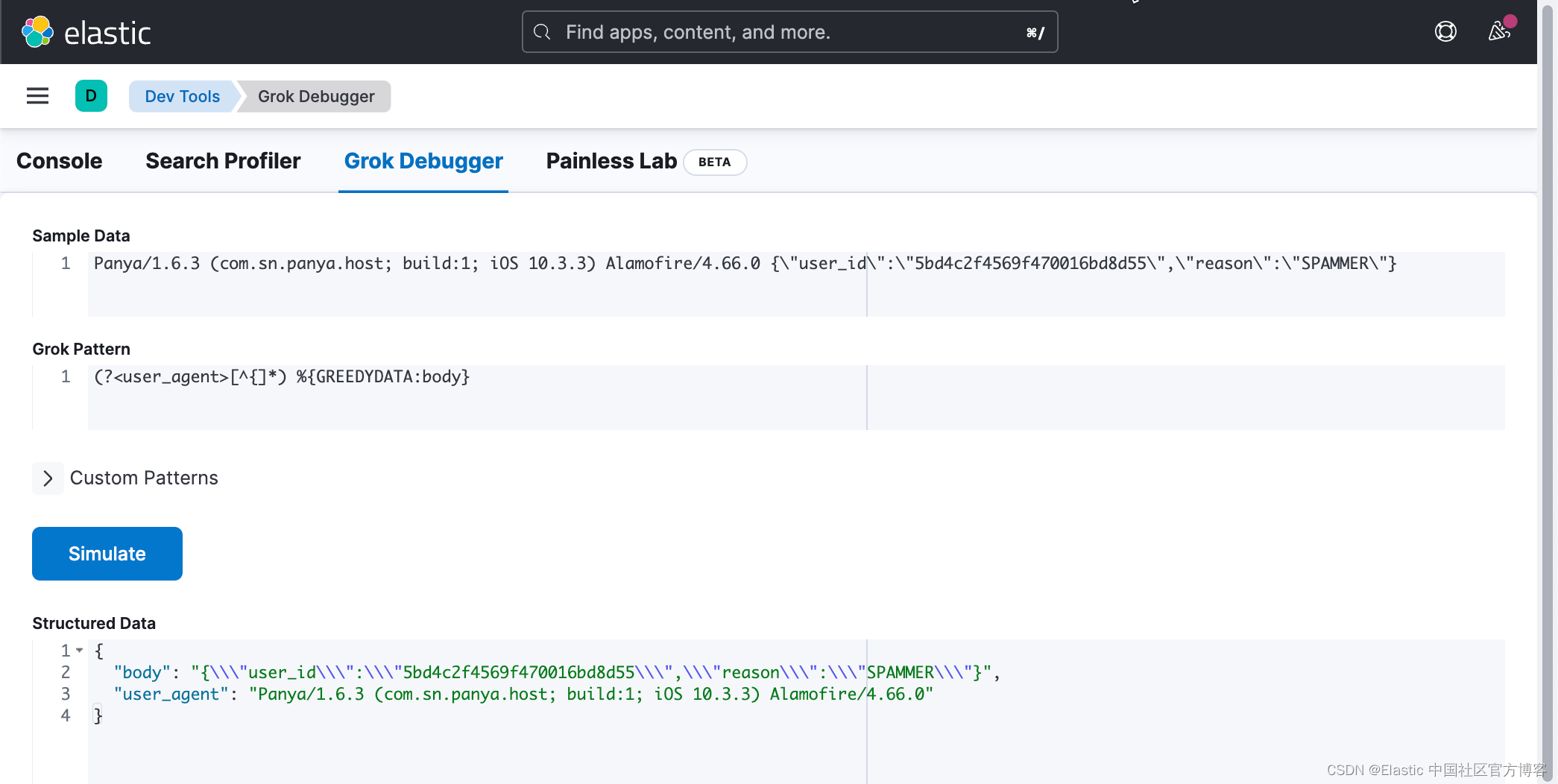
在上面,我们使用 Grok pattern:
(?<user_agent>[^{]*) %{GREEDYDATA:body}你可在这个链接中找到 “regex match everything until character”。
把所有的都放在一起
将其应用于 grok 调试器中的自定义正则表达式模式,我们得到了我们想要的结果:
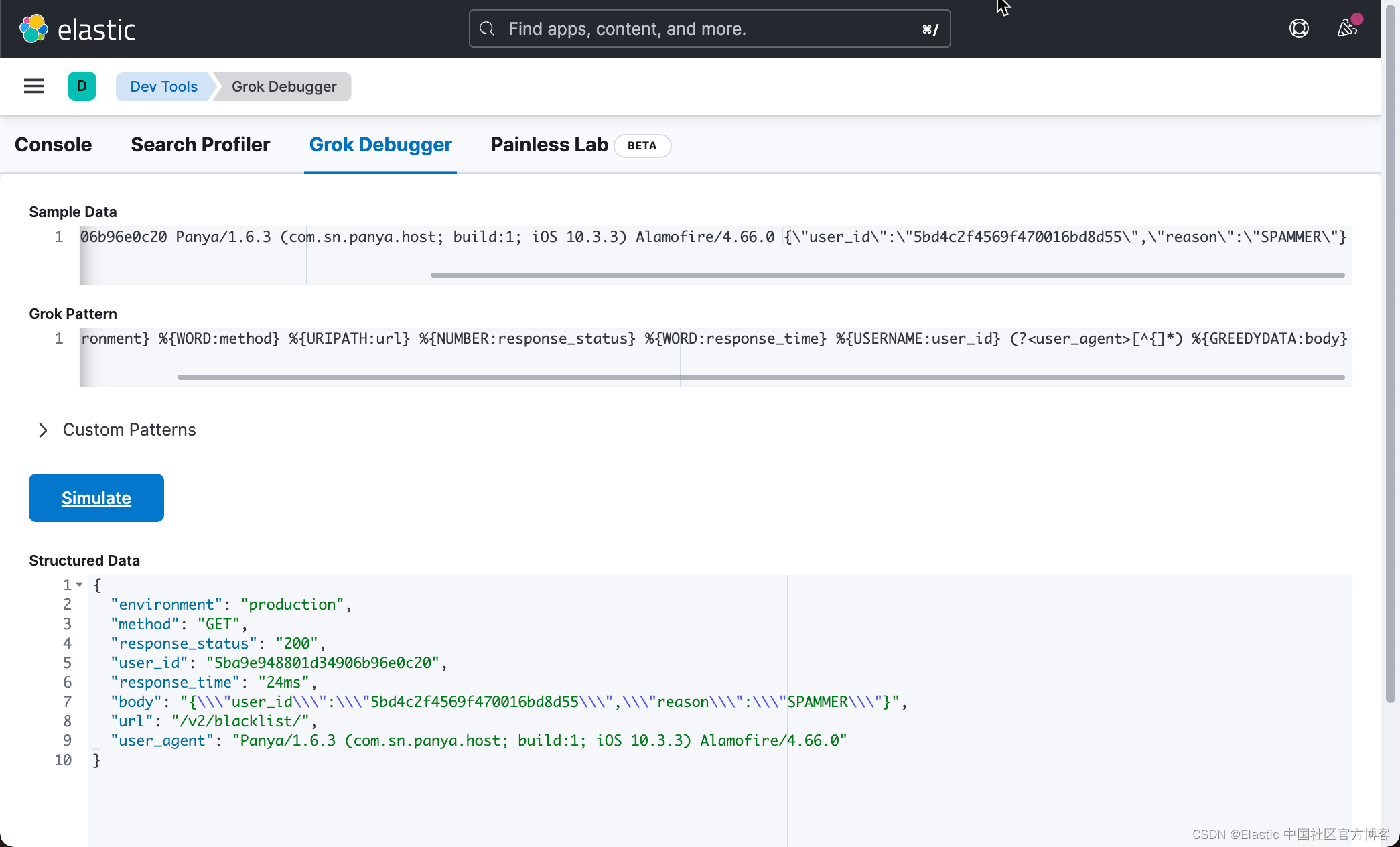
我们的 Grok pattern 为:
%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id} (?<user_agent>[^{]*) %{GREEDYDATA:body}
创建 logstash.conf
为了能够测试我们的 Grok pattern 是否正确,我们创建如下的一个 logstash.conf 文件。我们可以参考之前的文章 “Logstash:在实施之前测试 Logstash 管道/过滤器”。
logstash.conf
input {generator {message => 'production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 {"user_id":"5bd4c2f4569f470016bd8d55","reason":"SPAMMER"}'count => 1}
}filter {grok {match => { "message" => "%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id1} (?<user_agent>[^{]*) %{GREEDYDATA:body}"}}mutate {remove_field => ["message", "event", "host", "@version"]}
} output {stdout {codec => rubydebug}
}我们使用如下的命令来启动 Logstash pipeline:
./bin/logstash -f logstash.conf
从上面的输出中,我们可以看出来原始的数据已经变为结构化的数据了。我们可以看到美中不足的是 body 这个数据是一个 JSON 格式的数据,还没有被结构化。我们进一步修改我们的 logstash.conf 配置文件:
logstash.conf
input {generator {message => 'production GET /v2/blacklist/ 200 24ms 5ba9e948801d34906b96e0c20 Panya/1.6.3 (com.sn.panya.host; build:1; iOS 10.3.3) Alamofire/4.66.0 {"user_id":"5bd4c2f4569f470016bd8d55","reason":"SPAMMER"}'count => 1}
}filter {grok {match => { "message" => "%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id1} (?<user_agent>[^{]*) %{GREEDYDATA:body}"}}json {source => "body"}mutate {remove_field => ["message", "event", "host", "@version", "body"]}} output {stdout {codec => rubydebug}
}在上面,我们添加了 json 过滤器来处理 body,从而更进一步结构化数据。我们再次运行 Logstash。我们可以看到如下的结果:

从上面,我们可以看到 body 也被结果化了。我们可以看到 user_id 及 reason 两个字段。