苹果id钓鱼网站怎么做招聘网站排名
自然语言处理相关名词整理
- 零样本学习(zero-shot learning)
- 词嵌入(Embedding)
- 为什么 Embedding 搜索比基于词频搜索效果好?
- Word2Vec
- Transformer
- 检索增强生成(RAG)
- 幻觉
- 采样
- 温度
- Top-k
- Top-p
- 奖励模型
- 提示词(prompt)
- 微调
- Text-to-SQL(Text2SQL)
零样本学习(zero-shot learning)
零样本学习(Zero-shot learning)是一种机器学习方法,其目标是在没有样本示例的情况下,通过将新的类别或任务与已知的类别或任务相关联,来进行分类或执行其他任务。在传统的监督学习中,模型在训练阶段需要大量标记数据来学习不同类别之间的特征和模式。然而,在零样本学习中,模型被要求处理未见过的类别或任务,而不需要事先见过这些类别的训练样本。
零样本学习通常依赖于将类别之间的语义关系纳入模型的训练中,例如使用自然语言处理中的词向量模型(如Word2Vec、GloVe等)来表示类别之间的语义相似性。通过将这种语义信息与视觉特征相结合,可以帮助模型在没有见过新类别的情况下进行推断和泛化。
零样本学习的应用包括自然语言处理中的零样本文本分类、计算机视觉中的零样本图像识别等。这种方法的发展对于解决实际问题中遇到的数据稀缺或类别不平衡等挑战具有重要意义。
词嵌入(Embedding)
Embedding 是将离散的非结构化数据转换为连续的向量表示的技术。
在自然语言处理中,Embedding 常常用于将文本数据中的单词、句子或文档映射为固定长度的实数向量,使得文本数据能够在计算机中被更好地处理和理解。通过 Embedding,每个单词或句子都可以用一个实数向量来表示,这个向量中包含了该单词或句子的语义信息。这样,相似的单词或句子就会在嵌入空间中被映射为相近的向量,具有相似语义的词语或句子在向量空间上的距离也会较近。这使得在进行自然语言处理任务时,可以通过计算向量之间的距离或相似度来进行词语或句子的匹配、分类、聚类等操作。
为什么 Embedding 搜索比基于词频搜索效果好?
基于词频搜索的传统算法包括如 TF-IDF、BM25。词频搜索只考虑了词语在文本中的频率,而忽略了词语之间的语义关系。而 Embedding 搜索通过将每个词语映射到一个向量空间中的向量表示,可以捕捉到词语之间的语义关系。因此,当搜索时,可以通过计算词语之间的相似度来更准确地匹配相关的文本。
使用基于词频的搜索方法,如果我们查询 “cat”,那么结果中可能会将包含 “cat” 词频较高的文章排在前面。但是这种方法无法考虑到 “cat” 与其他动物的语义关系,比如与 “British Shorthair(英国短毛猫)”、“Ragdoll(布偶猫)” 等相似的动物。而使用 Embedding 搜索方法,可以将单词映射到高维空间中的向量,使得语义相似的单词在空间中距离较近。当我们查询 “cat” 时,Embedding 搜索可以找到与 “cat” 语义相似的单词,如 “British Shorthair”、“Ragdoll” 等,并将这些相关文章排在结果的前面。这样就能提供更准确、相关性更高的搜索结果。
Word2Vec
Word2Vec是一种用于将单词表示为连续向量空间中的密集向量的技术。在训练Word2Vec模型时,通过优化模型的参数,使得在向量空间中相似的单词具有相似的向量表示。这样,词向量之间的距离可以反映出单词之间的语义相似性。
Transformer
Transformer 是一种基于自注意力机制(self-attention)的神经网络模型,最早在 2017 年由 Google 的研究员提出并应用于自然语言处理任务。它能够对输入句子中不同位置的单词关系进行建模,从而更好地捕捉上下文信息。
检索增强生成(RAG)
检索增强生成(Retrieval Augmented Generation, RAG)是一种技术,它通过从数据源中检索信息来辅助大语言模型(Large Language Model, LLM)生成答案。简而言之,RAG 结合了搜索技术和大语言模型的提示词功能,即向模型提出问题,并以搜索算法找到的信息作为背景上下文,这些查询和检索到的上下文信息都会被整合进发送给大语言模型的提示中。
幻觉
幻觉问题是指生成的语言模型(Language Model)产生的输出与实际事实不符合,或者在特定上下文中缺乏准确性和一致性的现象。这些问题可能由于多种因素导致,包括模型的数据偏见、训练数据中的错误、模型的局限性等。
幻觉问题可能表现为以下一些情况:
- 错误的事实陈述:模型生成的语言可能包含错误的事实陈述,与真实世界中的情况不符。
- 语义模糊:模型生成的语言可能存在模糊的语义表达,导致理解困难或产生歧义。
- 不一致性:在相同的上下文中,模型可能产生不一致的输出,或者在类似的情境下提供不同的答案。
- 偏见性:模型可能会反映其训练数据中存在的偏见,导致生成的文本具有性别、种族、地域等方面的偏见。
- 不合逻辑:生成的文本可能缺乏逻辑性,包含自相矛盾的内容或不合理的推理。
采样
在自然语言处理中,"采样"通常指的是从模型的输出分布中随机选择一个元素或样本的过程。在生成式模型中,尤其是语言模型,采样通常用于从模型生成的概率分布中选择下一个单词或标记。
在语言模型中,生成的文本通常由一个词序列组成。每个词在给定前面词序列的条件下,都有一个对应的条件概率分布。采样过程就是根据这个概率分布从候选词汇中选择下一个词。
常见的采样方法包括:
- 贪婪采样(Greedy Sampling):直接选择具有最高概率的词作为下一个词。这种方法简单直接,但可能导致模型生成重复、无意义或不连贯的文本。
- 随机采样(Random Sampling):根据每个词的概率分布,随机选择一个词作为下一个词。这种方法使得生成的文本更加多样化,但可能会导致一些稀有词被选择的机会较小。
- 温度采样(Temperature Sampling):通过调整温度参数,可以控制采样过程中的随机性。较高的温度会使得模型更加随机地选择词,而较低的温度会使得模型更加倾向于选择概率较高的词。
- 核心词采样(Nucleus Sampling):根据累积概率分布,从一组最高概率的词中随机选择一个词。这种方法可以平衡生成文本的多样性和概率高的词的选择。
采样方法的选择取决于应用场景和需求。贪婪采样适用于速度要求较高、多样性要求不高的情况;随机采样适用于希望生成多样化文本的场景;温度采样和核心词采样则提供了在多样性和概率控制之间的平衡。
温度
通过调整温度参数,可以控制采样过程中的随机性。较高的温度会使得模型更加随机地选择词,而较低的温度会使得模型更加倾向于选择概率较高的词。
Top-k
它是基于随机采样的一种改进,旨在增加生成文本的多样性和可控性。
在Top-K采样中,首先根据模型预测的概率分布对词汇表中的单词进行排序,然后选择排名在前K个位置的单词作为候选集。接下来,根据这K个单词的概率分布进行随机采样,选择其中一个单词作为下一个生成的单词。换句话说,Top-K采样通过限制候选集合来平衡了生成文本的多样性和概率的控制。
与传统的随机采样相比,Top-K采样的优点在于:
- 控制多样性:Top-K采样通过限制候选单词集合,可以在一定程度上控制生成文本的多样性,使得生成的文本更加丰富和多样。
- 减少噪声:相比于完全随机的采样,Top-K采样通过选择概率较高的候选单词,可以降低生成文本中的噪声和不连贯性。
- 可预测性:Top-K采样可以通过调整参数K来控制采样的行为,使得生成文本的结果更加可预测和可控。
在实际应用中,Top-K采样常常与其他采样技术结合使用,如温度采样(Temperature Sampling)或核心词采样(Nucleus Sampling),以达到更好的效果。
Top-p
Top-p 采样(也称为核心采样)允许更动态地选择要从中采样的值。
在 Top-p 采样中,模型按概率降序对最可能的下一个值求和,并在总和达到 p 时停止。只有在这个累积概率范围内的值才会被考虑。语言模型中常见的 Top-p(核心)采样值通常介于 0.9 到 0.95 之间。
例如,Top-p 值为 0.9 意味着模型将考虑累积概率超过 90% 的最小的一组值。
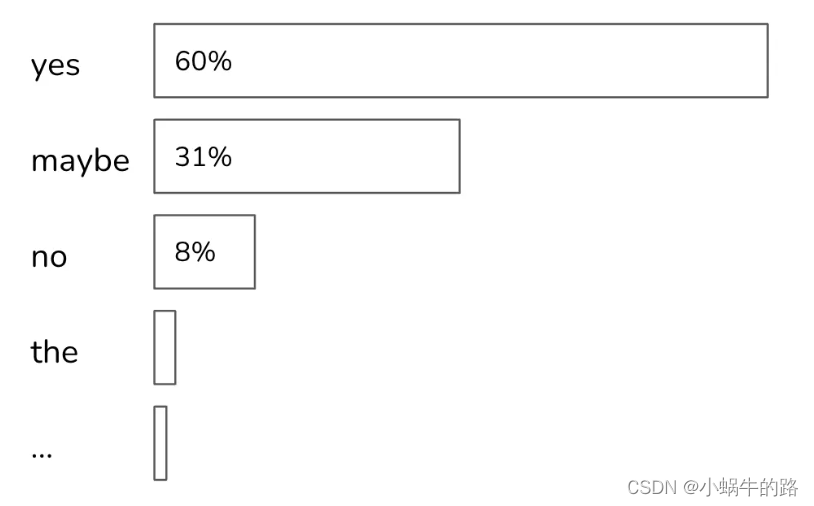
假设所有词元的概率如下图所示。如果 top_p=90%,那么只有 “yes” 和 “maybe” 会被考虑,因为它们的累积概率大于 90%。如果 top_p=99%,那么将考虑 “yes”、“maybe” 和 “no”。
奖励模型
是指在强化学习中,用于描述和计算行为的奖励值的模型。在强化学习中,智能体(Agent))通过不断地与环境进行交互,从中获得一定的奖励值。
奖励模型可以描述和计算每一次交互中智能体获得的奖励值,并且根据这些奖励值,智能体可以学习到如何更好地进行决策,从而获得更高的累积奖励值。
奖励模型是强化学习中的一个重要概念,它直接影响智能体的学习效果和行为表现。好的奖励模型能够帮助智能体更快、更准确地完成任务。但如果奖励模型不合理或存在偏差,将会导致智能体学习出错误的行为或无法学习出有效的行为。因此,设计合理的奖励模型是强化学习中的一个重要挑战。
提示词(prompt)
提示词通常指的是一种文本输入方式,用于引导模型生成符合特定要求或意图的文本。这种输入方式通常通过在模型输入的开头提供一些关键词或短语,以指示模型在生成文本时应该遵循的方向或主题。
提示词在LLM中可以与其他输入方式(如上下文信息、条件信息等)结合使用,以更精确地引导模型生成期望的文本输出。通过合理设计和使用提示词,可以提高LLM生成文本的准确性、一致性和可控性。
微调
微调模型是指在已经训练好的机器学习模型的基础上,通过少量的新数据或调整模型的参数,来对模型进行进一步的训练以适应特定任务或数据集。
微调模型的优点在于可以充分利用预训练模型在大规模数据上学到的通用特征,并通过少量数据的微调,使得模型更好地适应特定任务或数据集。这种方法通常能够带来更好的性能和更快的训练速度,尤其适用于数据量较小的情况下。
Text-to-SQL(Text2SQL)
把文本转化为 SQL 语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,简写为 NL)问题,转化为在关系型数据库中可以执行的结构化查询语言(Structured Query Language,简写为 SQL)。