100m网站空间服务费发布软文
目录
一、实验目的
二、实验环境
三、实验内容
3.1 训练模型,通过调整超参数、使用不同优化器,并对比训练结果
3.1.1 LeNet模型
3.1.2 AlexNet模型
3.1.3 VGG模型
3.1.4 ResNet模型
3.2 调整AlexNet模型
3.2.1 简化模型
3.2.2 设计模型以便可以直接在28*28图像上工作
一、实验目的
- 了解python语法
- 运行LeNet\AlexNet\VGG\ResNet源码,调整超参数、选择其它优化器等,比较实验结果。
- 简化AlexNet模型以加快训练速度,同时确保准确性不会显著下降,对比模型精度变化。
二、实验环境
Baidu 飞桨AI Studio
三、实验内容
3.1 训练模型,通过调整超参数、使用不同优化器,并对比训练结果
3.1.1 LeNet模型
(1)代码分析:
import torch
from torch import nn
from d2l import torch as d2l
import os
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape: \t',X.shape)import torchvision
from torchvision import transforms
from torch.utils import data
def get_dataloader_workers():return 4
def load_data_fashion_mnist(batch_size, resize=None):trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size=batch_size)def evaluate_accuracy_gpu(net, data_iter, device=None): #@saveif isinstance(net, nn.Module):net.eval() if not device:device = next(iter(net.parameters())).devicemetric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()timer, num_batches = d2l.Timer(), len(train_iter)total_loss = d2l.Accumulator(2) total_acc = d2l.Accumulator(2) for epoch in range(num_epochs):metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])total_loss.add(l * X.shape[0], X.shape[0])total_acc.add(d2l.accuracy(y_hat, y), y.numel())timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:print(f'Epoch {epoch + 1}, Batch {i + 1}/{num_batches},'f'Loss: {train_l:.3f}, Train Acc: {train_acc:.3f}')test_acc = evaluate_accuracy_gpu(net, test_iter)print(f'Epoch {epoch + 1}, Test Acc: {test_acc:.3f}')print(f'Total loss: {total_loss[0]:.3f}, Total accuracy: {total_acc[0] / total_acc[1]:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())代码部分实现了卷积神经网络CNN对FashionMNIST数据集的分类任务,并使用PyTorch进行训练和评估模型。
代码中定义网络结构为两个包含激活函数的卷积层、两个平均池化层、一个展平层和三个带有激活函数的全连接层。遍历网络结构的每个层并打印每层的输出形状。
定义数据集的数据加载器并进行预处理。并设置了评估函数用于在GPU上评估模型的准确性,设置训练函数,其中使用随机梯度下降(SGD)和交叉熵损失函数更新参数,最后打印训练和测试的损失及准确率。
代码中定义的学习率lr=0.9,训练轮数num_epochs=10,可以通过调整超参数调整模型。
(2)调整模型、 对比实验结果:
原模型的优化器使用了 torch.optim.SGD(随机梯度下降)
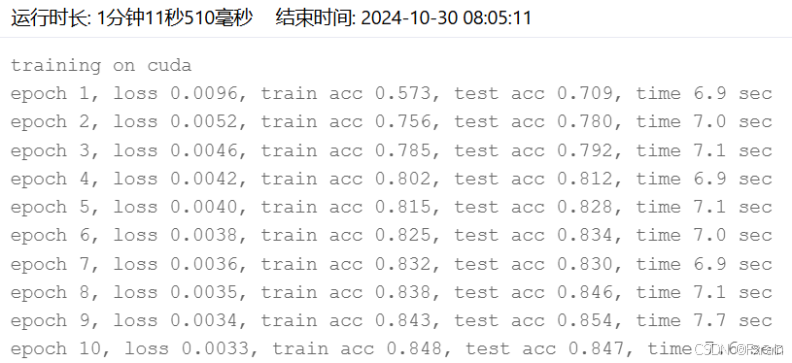
- 学习率lr=0.9 训练轮数num_epochs=10 批量大小batch_size=256,结果如图1所示,原模型训练结果图中展示了每个批次的训练损失和准确率以及每个epoch结束后的测试准确率,最后计算总损失及准确率。
- 调整模型,将优化器修改为 Adam 优化器,结果如图2所示。
- 设置学习率lr=0.01,不改变训练轮数num_epochs=10和批量大小batch_size=256,结果图如图3所示。同样设置学习率lr=1.5,不改变其它参数,结果如图4所示。设置学习率lr=3,不改变其它参数,结果如图5所示。
- 设置训练轮数num_epochs=20,不改变学习率lr=0.9和批量大小batch_size=256,结果图如图6所示。同样设置训练轮数num_epochs=100,不改变其它参数,结果如图7所示。设置训练轮数num_epochs=150,不改变其它参数,结果如图8所示。
- 设置批量大小batch_size=128,不改变学习率lr=0.9和训练轮数num_epochs=10,结果如图9所示。同样设置批量大小batch_size=512,不改变其它参数,结果如图10所示。
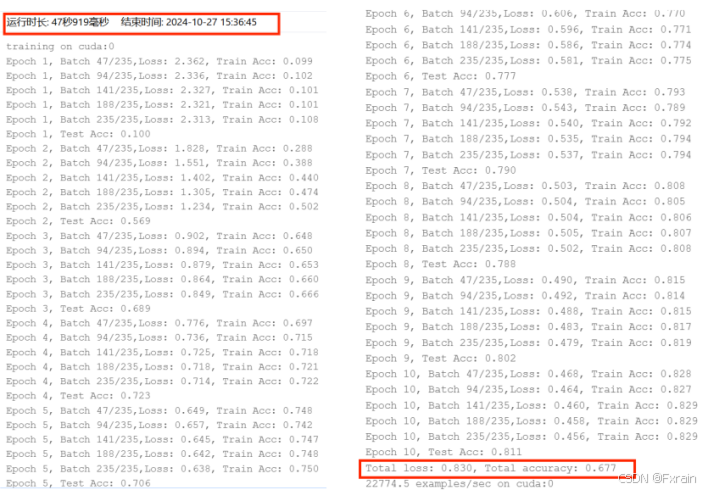
图 1 SGD优化器 学习率lr=0.9 训练轮数num_epochs=10 批量大小batch_size=256

图 2 Adam优化器 学习率lr=0.9 训练轮数num_epochs=10 批量大小batch_size=256

图 3 SGD优化器 学习率lr=0.01 训练轮数num_epochs=10 批量大小batch_size=256

图 4 SGD优化器 学习率lr=1.5 训练轮数num_epochs=10 批量大小batch_size=256

图 5 SGD优化器 学习率lr=3 训练轮数num_epochs=10 批量大小batch_size=256

图 6 SGD优化器 学习率lr=0.9 训练轮数num_epochs=20 批量大小batch_size=256
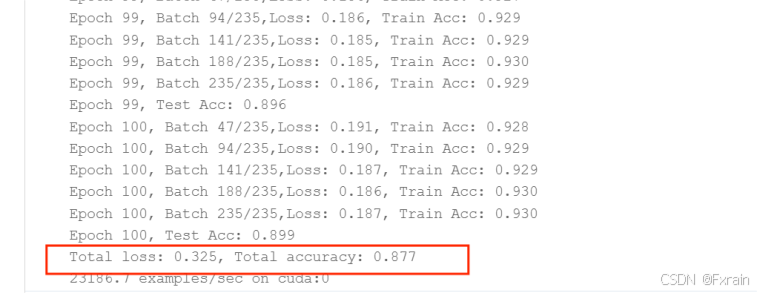
图 7 SGD优化器 学习率lr=0.9 训练轮数num_epochs=100 批量大小batch_size=256
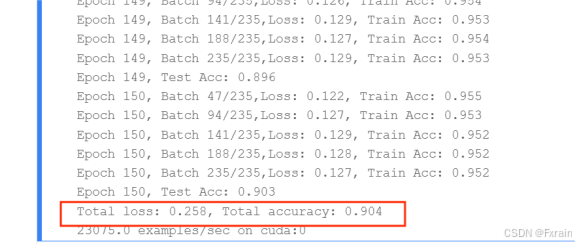
图 8 SGD优化器 学习率lr=0.9 训练轮数num_epochs=150 批量大小batch_size=256

图 9 SGD优化器 学习率lr=0.9 训练轮数num_epochs=10 批量大小batch_size=128
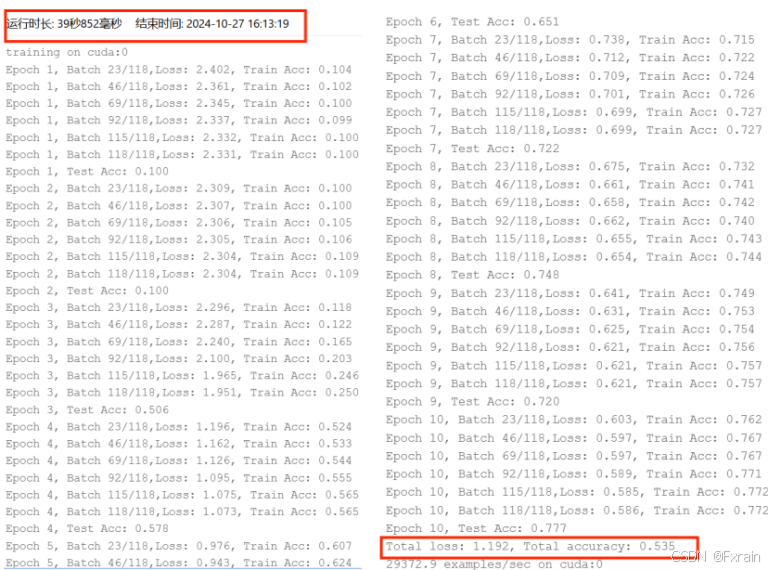
图 10 SGD优化器 学习率lr=0.9 训练轮数num_epochs=10 批量大小batch_size=512
(3)绘制表格并分析实验结果,如表1所示:
对比实验结果可知,对于Fashion-MNIST数据集,使用SGD优化器的模型整体准确率高于使用Adam优化器的模型;其次,实验中学习率在一定范围内适当地提高有利于降低平均损失率,提高模型的准确率,效率也有所提高;对于训练轮数,较小的训练轮数节省了时间和计算资源,较大的训练轮数使模型更好地拟合训练数据,但是计算成本高,需要更多的计算时间;对于批量大小,较小的批量大小导致模型训练时间更长,增加了损失波动,同时模型的准确率也有所提高。较大的批量大小由于减少了批次的数量,计算量减少,训练时间更短。
| 优化器 | 学习率lr | 训练轮数num_epochs | 批量大小batch_size | 平均损失率total loss | 整体准确率total accuracy | 运行时间 |
| SGD | 0.9 | 10 | 256 | 0.830 | 0.677 | 47秒919毫秒 |
| Adam | 0.9 | 10 | 256 | 9.646 | 0.100 | 44秒949毫秒 |
| SGD | 0.01 | 10 | 256 | 2.304 | 0.098 | 44秒193毫秒 |
| SGD | 1.5 | 10 | 256 | 0.889 | 0.656 | 44秒131毫秒 |
| SGD | 3 | 10 | 256 | 1.387 | 0.461 | 44秒550毫秒 |
| SGD | 0.9 | 20 | 256 | 0.625 | 0.761 | 1分钟27秒561毫秒 |
| SGD | 0.9 | 100 | 256 | 0.325 | 0.877 | 7分钟19秒805毫秒 |
| SGD | 0.9 | 150 | 256 | 0.258 | 0.904 | 11分钟1秒254毫秒 |
| SGD | 0.9 | 10 | 128 | 0.716 | 0.724 | 55秒145毫秒 |
| SGD | 0.9 | 10 | 512 | 1.192 | 0.535 | 39秒852毫秒 |
3.1.2 AlexNet模型
(1)代码分析:
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 10))X = torch.randn(1, 1, 224, 224)
for layer in net:X=layer(X)print(layer.__class__.__name__,'output shape:\t',X.shape)import torchvision
from torchvision import transforms
from torch.utils import data
def get_dataloader_workers():return 4
def load_data_fashion_mnist(batch_size, resize=None):trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))
batch_size = 128
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=224)
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())代码中定义了基于AlexNet的神经网络。第一层是卷积层,使用96个11x11的滤波器,步幅为4,填充为1。第二层是最大池化层,使用3x3的窗口,步幅为2。第三层是卷积层,使用256个5x5的滤波器,填充为2。第四层是最大池化层,使用3x3的窗口,步幅为2。第五到第七层是两个卷积层,每个使用384个3x3的滤波器,填充为1。第八层是另一个卷积层,使用256个3x3的滤波器,填充为1。第九层是最大池化层,使用3x3的窗口,步幅为2。第十层是展平层,将多维张量展平成一维向量。第十一到第十三层是三个全连接层,分别有4096个神经元,并使用ReLU激活函数和Dropout正则化。最后一层是输出层,有10个神经元,对应于10个类别。对于数据加载及预处理后训练模型,代码中设置学习率lr为0.01,设置训练轮数num_epochs为10,可以通过调整超参数调整模型。
(2)调整模型、 对比实验结果:
a.原模型的优化器使用了 torch.optim.SGD(随机梯度下降)
学习率lr=0.01 训练轮数num_epochs=10 批量大小batch_size=128 工作线程数=4
结果如图11所示,原模型训练结果图中展示了每个批次的训练损失和准确率以及每个epoch结束后的测试准确率,最后计算总损失及准确率。
b.调整模型,将优化器修改为 Adam 优化器,结果如图12所示。
c.设置学习率lr=0.001,不改变训练轮数num_epochs=10和批量大小batch_size=128,结果图如图13所示。同样设置学习率lr=0.5,不改变其它参数,结果如图14所示。
d.设置训练轮数num_epochs=5,不改变学习率lr=0.01和批量大小batch_size=128,结果图如图15所示。同样设置训练轮数num_epochs=20,不改变其它参数,结果如图16所示。
e.设置批量大小batch_size=64,不改变学习率lr=0.01和训练轮数num_epochs=10,结果图如图17所示。同样设置batch_size=256,不改变其它参数,结果如图18所示。
f.设置工作线程数=8,不改变其他参数,结果如图19所示。

图 11 SGD优化器 学习率lr=0.01 训练轮数num_epochs=10 批量大小batch_size=128

图 12 Adam优化器 学习率lr=0.01 训练轮数num_epochs=10 批量大小batch_size=128

图 13 SGD优化器 学习率lr=0.001 训练轮数num_epochs=10 批量大小batch_size=128

图 14 SGD优化器 学习率lr=0.5 训练轮数num_epochs=10 批量大小batch_size=128

图 15 SGD优化器 学习率lr=0.01 训练轮数num_epochs=5 批量大小batch_size=128

图 16 SGD优化器 学习率lr=0.01 训练轮数num_epochs=20 批量大小batch_size=128
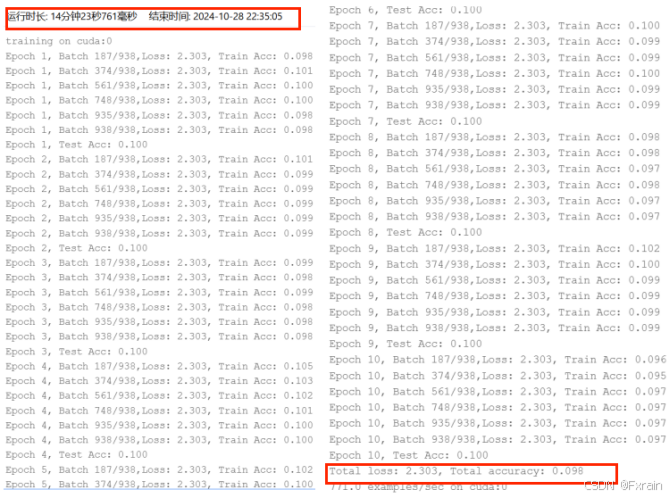
图 17 SGD优化器 学习率lr=0.01 训练轮数num_epochs=10 批量大小batch_size=64

图 18 SGD优化器 学习率lr=0.01 训练轮数num_epochs=10 批量大小batch_size=256

图 19 工作线程数=8
(3)绘制表格并分析实验结果,如表2所示:
对比实验结果可知,在使用AlexNet的模型中,使用SGD优化器的准确率高于使用Adam模型的准确率,但是准确率高的同时SGD优化器的运行时间更长;对比学习率从0.001到0.01再到0.5,适当增加学习率,模型的准确率会提高,平均损失有所降低,如果学习率过大,会造成模型精度下降,可能会导致模型过拟合;对比训练轮数从5到10再到20,增加训练轮数有利于模型提高准确率,但是同时计算时间增加,计算成本提高;对比批量大小从64到128再到256,从实验结果可以看出当批量大小设置为128时训练出的模型精度最高;当修改模型工作线程数从4到8,可以看到工作线程数的改变对模型损失率、准确率等并无较大影响。
| 优化器 | 学习率lr | 训练轮数num_epochs | 批量大小batch_size | 工作线程数 | 平均损失率total loss | 整体准确率total accuracy | 运行时间 |
| SGD | 0.01 | 10 | 128 | 4 | 0.530 | 0.804 | 29分钟32秒776毫秒 |
| Adam | 0.01 | 10 | 128 | 4 | 521.454 | 0.119 | 8分钟38秒433毫秒 |
| SGD | 0.001 | 10 | 128 | 4 | 1.280 | 0.536 | 7分钟37秒889毫秒 |
| SGD | 0.5 | 10 | 128 | 4 | 2.304 | 0.100 | 7分钟17秒594毫秒 |
| SGD | 0.01 | 5 | 128 | 4 | 2.303 | 0.100 | 3分钟35秒947毫秒 |
| SGD | 0.01 | 20 | 128 | 4 | 2.303 | 0.098 | 14分钟38秒794毫秒 |
| SGD | 0.01 | 10 | 64 | 4 | 2.303 | 0.098 | 14分钟23秒761毫秒 |
| SGD | 0.01 | 10 | 256 | 4 | 2.303 | 0.099 | 7分钟11秒752毫秒 |
| SGD | 0.01 | 10 | 128 | 8 | 0.528 | 0.805 | 7分钟46秒636毫秒 |
3.1.3 VGG模型
(1)代码分析:
import torch
from torch import nn
from d2l import torch as d2ldef vgg_block(num_convs, in_channels, out_channels):layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels,kernel_size=3, padding=1))layers.append(nn.ReLU())in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2,stride=2))return nn.Sequential(*layers)conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))def vgg(conv_arch):conv_blks = []in_channels = 1for (num_convs, out_channels) in conv_arch:conv_blks.append(vgg_block(num_convs, in_channels, out_channels))in_channels = out_channelsreturn nn.Sequential(*conv_blks, nn.Flatten(),nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(4096, 10))net = vgg(conv_arch)X = torch.randn(size=(1, 1, 224, 224))
for blk in net:X = blk(X)print(blk.__class__.__name__,'output shape:\t',X.shape)ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)代码中通过一个VGG网络处理FashionMNIST数据集,vgg_block函数定义了一个基本的VGG块,包含多个卷积层和ReLU激活函数,最后连接最大池化层。vgg函数根据conv_arch构建整个VGG网络,包括卷积块、展平层和全连接层。打印每一层输出的形状,以验证网络结构是否正确。通过将每个卷积层的输出通道数除以ratio来缩小模型的规模,并重新构建VGG网络。
加载训练数据集后进行模型训练,代码如上述两个模型所示,其中设置学习率、训练轮数和批量大小,可通过修改超参数调整网络模型。
(2)调整模型、 对比实验结果:
a.原模型的优化器使用了 torch.optim.SGD(随机梯度下降)
学习率lr=0.05 训练轮数num_epochs=10 批量大小batch_size=128 工作线程数=4
结果如图20所示,原模型训练结果图中展示了每个批次的训练损失和准确率以及每个epoch结束后的测试准确率,最后计算总损失及准确率。
b.调整模型,将优化器修改为 Adam 优化器,结果如图21所示。
c.设置学习率lr=0.5,不改变训练轮数num_epochs=10和批量大小batch_size=128,结果图如图22所示。同样设置学习率lr=0.001,不改变其它参数,结果如图23所示。
d.设置训练轮数num_epochs=5,不改变学习率lr=0.05和批量大小batch_size=128,结果图如图24所示。同样设置训练轮数num_epochs=20,不改变其它参数,结果如图25所示。
e.设置批量大小batch_size=64,不改变学习率lr=0.05和训练轮数num_epochs=10,结果图如图26所示。同样设置batch_size=256,不改变其它参数,结果如图27所示。
f.设置工作线程数=8,不改变其他参数,结果如图28所示。

图20 SGD优化器 学习率lr=0.05 训练轮数num_epochs=10 批量大小batch_size=128

图21 Adam优化器 学习率lr=0.05 训练轮数num_epochs=10 批量大小batch_size=128

图 22 SGD优化器 学习率lr=0.5 训练轮数num_epochs=10 批量大小batch_size=128

图 23 SGD优化器 学习率lr=0.001 训练轮数num_epochs=10 批量大小batch_size=128
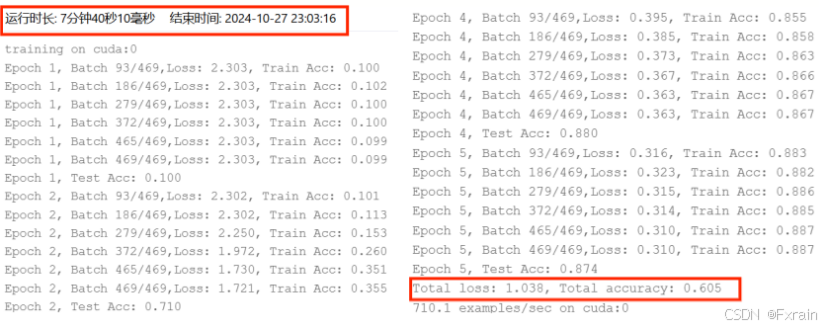
图 24 SGD优化器 学习率lr=0.05 训练轮数num_epochs=5 批量大小batch_size=128

图 25 SGD优化器 学习率lr=0.05 训练轮数num_epochs=20 批量大小batch_size=128

图 26 SGD优化器 学习率lr=0.05 训练轮数num_epochs=20 批量大小batch_size=64

图 27 SGD优化器 学习率lr=0.05 训练轮数num_epochs=20 批量大小batch_size=256

图 28 工作线程数=8
(3)绘制表格并分析实验结果,如表3所示:
对比实验结果可知,在VGG模型中使用SGD优化器的准确率高于使用Adam模型的准确率,但是准确率高的同时SGD优化器的运行时间更长;对比学习率从0.001到0.05再到0.5,当学习率设置为0.05时模型的精度最高,损失函数最小;对比训练轮数从5到10再到20,随着训练轮数的增加,平均损失率逐渐降低,准确率逐渐增加;对比批量大小从64到128再到256,从实验结果可以看到,当批量大小设置为64时准确率最高,平均损失最低,设置为128和256的准确率相近,但是批量大小为128的模型平均损失略低于批量大小为256的模型;修改工作线程数,可以看到结果相近,并无较大变化。
| 优化器 | 学习率lr | 训练轮数num_epochs | 批量大小batch_size | 工作线程数 | 平均损失率total loss | 整体准确率total accuracy | 运行时间 |
| SGD | 0.05 | 10 | 128 | 4 | 0.352 | 0.870 | 15分钟17秒868毫秒 |
| Adam | 0.5 | 10 | 128 | 4 | 1643696.607 | 0.099 | 15分钟49秒290毫秒 |
| SGD | 0.5 | 10 | 128 | 4 | 2.304 | 0.100 | 14分钟50秒651毫秒 |
| SGD | 0.001 | 10 | 128 | 4 | 2.303 | 0.100 | 15分钟6秒617毫秒 |
| SGD | 0.05 | 5 | 128 | 4 | 1.038 | 0.605 | 7分钟40秒10毫秒 |
| SGD | 0.05 | 20 | 128 | 4 | 0.253 | 0.929 | 31分钟26秒497毫秒 |
| SGD | 0.05 | 10 | 64 | 4 | 0.257 | 0.906 | 16分钟25秒780毫秒 |
| SGD | 0.05 | 10 | 256 | 4 | 0.401 | 0.852 | 13分钟45秒150毫秒 |
| SGD | 0.05 | 10 | 128 | 8 | 0.365 | 0.866 | 15分钟27秒249毫秒 |
3.1.4 ResNet模型
(1)代码分析:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lclass Residual(nn.Module): #@savedef __init__(self, input_channels, num_channels,use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels,kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels,kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels,kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)blk = Residual(3,3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.Shapeblk = Residual(3,6, use_1x1conv=True, strides=2)
blk(X).shape
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))def resnet_block(input_channels, num_channels, num_residuals,first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels,use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))
return blkb2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(), nn.Linear(512, 10))X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape:\t', X.shape)代码中通过基于ResNet架构的卷积神经网络处理FashionMNIST数据集。Residual类定义了一个残差块,它包含两个卷积层和一个可选的1x1卷积层(用于改变输入和输出的维度)。forward方法中,首先通过第一个卷积层和批量归一化层,再通过ReLU激活函数。接着,第二个卷积层和批量归一化层,最后将输入与输出相加,并通过ReLU激活函数。ResNet网络中包含卷积层、批量归一化层、ReLU激活函数、最大池化层,以及不同深度的残差块序列,还包括展平层和全连接层。
加载训练数据集后进行模型训练,具体代码见百度飞桨平台。其中设置学习率、训练轮数和批量大小,可通过修改超参数调整网络模型。
(2)调整模型、 对比实验结果:
a.原模型的优化器使用了 torch.optim.SGD(随机梯度下降)
学习率lr=0.05 训练轮数num_epochs=10 批量大小batch_size=256 工作线程数=4
结果如图29所示,原模型训练结果图中展示了每个批次的训练损失和准确率以及每个epoch结束后的测试准确率,最后计算总损失及准确率。
b.调整模型,将优化器修改为 Adam 优化器,结果如图30所示。
c.设置学习率lr=0.001,不改变训练轮数num_epochs=10和批量大小batch_size=256,结果图如图31所示。同样设置学习率lr=0.5,不改变其它参数,结果如图32所示。
d.设置训练轮数num_epochs=5,不改变学习率lr=0.05和批量大小batch_size=256,结果图如图33所示。同样设置训练轮数num_epochs=20,不改变其它参数,结果如图34所示。
e.设置批量大小batch_size=128,不改变学习率lr=0.05和训练轮数num_epochs=10,结果图如图35所示。同样设置batch_size=512,不改变其它参数,结果如图36所示。
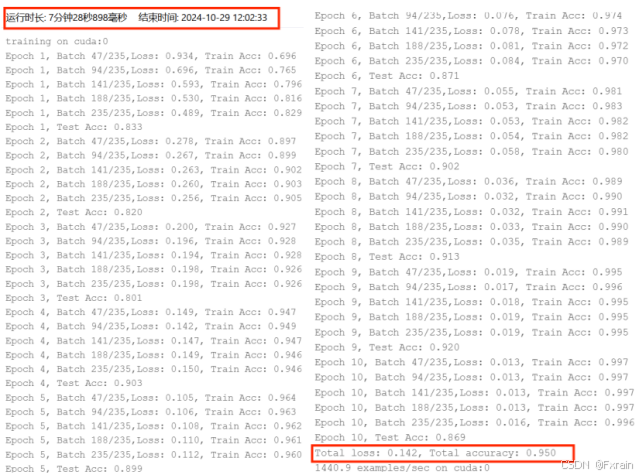
图 29 SGD优化器 学习率lr=0.05 训练轮数num_epochs=10 批量大小batch_size=256

图 30 Adam优化器 学习率lr=0.05 训练轮数num_epochs=10 批量大小batch_size=256

图 31 SGD优化器 学习率lr=0.001 训练轮数num_epochs=10 批量大小batch_size=256

图 32 SGD优化器 学习率lr=0.5 训练轮数num_epochs=10 批量大小batch_size=256

图 33 SGD优化器 学习率lr=0.5 训练轮数num_epochs=5 批量大小batch_size=256

图 34 SGD优化器 学习率lr=0.5 训练轮数num_epochs=20 批量大小batch_size=256

图 35 SGD优化器 学习率lr=0.5 训练轮数num_epochs=20 批量大小batch_size=128

图 36 SGD优化器 学习率lr=0.5 训练轮数num_epochs=20 批量大小batch_size=512
(3)绘制表格并分析实验结果,如表4所示:
对比实验结果可知,对于ResNet模型,使用SGD优化器的模型精度高于使用Adam优化器的模型;对于学习率从0.001到0.05再到0.5,学习率为0.05时的模型精度最高,平均损失最小;对于训练轮数从5到10再到20,训练轮数越大,模型精度越高,但是可以看到,模型的计算成本明显提高;对于批量大小从128到256再到512,从实验结果可以看到,三个批量大小的改变对ResNet的影响较小。
| 优化器 | 学习率lr | 训练轮数num_epochs | 批量大小batch_size | 平均损失率total loss | 整体准确率total accuracy | 运行时间 |
| SGD | 0.05 | 10 | 256 | 0.142 | 0.950 | 7分钟28秒898毫秒 |
| Adam | 0.05 | 10 | 256 | 0.503 | 0.872 | 7分钟31秒677毫秒 |
| SGD | 0.001 | 10 | 256 | 0.466 | 0.847 | 7分钟28秒397毫秒 |
| SGD | 0.5 | 10 | 256 | 0.330 | 0.887 | 7分钟27秒795毫秒 |
| SGD | 0.05 | 5 | 256 | 0.230 | 0.917 | 3分钟47秒152毫秒 |
| SGD | 0.05 | 20 | 256 | 0.069 | 0.976 | 15分钟8秒623毫秒 |
| SGD | 0.05 | 10 | 128 | 0.127 | 0.954 | 7分钟54秒979毫秒 |
| SGD | 0.05 | 10 | 512 | 0.161 | 0.944 | 7分钟31秒159毫秒 |
3.2 调整AlexNet模型
3.2.1 简化模型
原AlexNet模型具有五层卷积层,一个最大池化层(大小为3*3,步幅为2),三个全连接层(16400个输入节点,4096个输出节点24096个输入节点,4096个输出节点34096个输入节点,10个输出节点),两个Dropout层(丢弃率为0.5)。
修改模型网络结构如以下代码所示,修改为四个卷积层,修改的模型中第一层卷积层的卷积核是7*7,一个最大池化层,大小为3*3,步幅为2,两个全连接层(1256*13*13个输入节点,1024个输出节点21024个输入节点,10个输出节点),一个Dropout层(丢弃率为0.5)。
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(64, 128, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(256 * 13 * 13, 1024), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(1024, 10))原模型打印处每一层的形状:

修改后的模型打印出的每一层的形状:

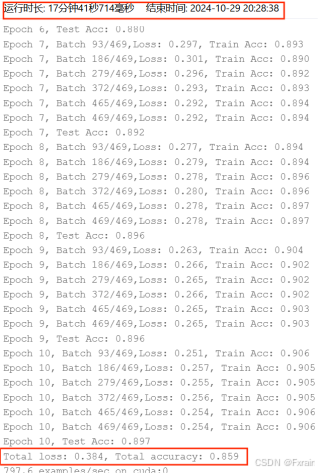
结果如图所示:根据3.1中的实验结果,原模型运行时长为29分钟,修改后的模型运行时长为17分钟,模型的效率有所提高。
3.2.2 设计模型以便可以直接在28*28图像上工作
如以下代码所示,设计网络结构包含两个卷积层、两个ReLU激活函数,两个最大池化层、一个展平层、一个全连接层、一个Dropout层和一个输出层。
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.flatten = nn.Flatten()self.fc1 = nn.Linear(64 * 7 * 7, 1024)self.relu3 = nn.ReLU()self.dropout = nn.Dropout(p=0.5)self.fc2 = nn.Linear(1024, 10)def forward(self, x):x = self.conv1(x)x = self.relu1(x)x = self.pool1(x)x = self.conv2(x)x = self.relu2(x)x = self.pool2(x)x = self.flatten(x)x = self.fc1(x)x = self.relu3(x)x = self.dropout(x)x = self.fc2(x)return x
net = Net()结果如下图所示: