怎么做网页粗略布局图厦门seo推广
文章目录
- 1、MySQL-MVCC
- 2、MySQL-原子性怎么实现
- 3、MySQL-持久性怎么实现
- 隔离性怎么实现
- 4、操作系统-死锁产生
- 手写死锁
- 死锁排查
- 5、操作系统-避免死锁
- 死锁的四个必要条件
- 预防死锁
- 6、操作系统-pageCache是什么
- 零拷贝
- 7、计算机网络-TCP的可靠性和顺序性怎么实现
- 8、计算机网络-怎么进行流量控制
- 9、Redis-怎么持久化的数据
- RDB和AOF的区别
- AOF三种回写策略
- 10、Redis-集群是怎么做的?就是数据怎么分片的,然后它的集群的高可用是什么?怎么部署的,这个有没有了解过?
- 11、分布式-分布式事务是什么
- 分布式两大理论
- 分布式锁
- 12、分布式-paxos和raft的区别
- 13、分布式-为什么就是分布式的共识算法都需要要求多数派提交才能完成它的分布式一致性?
- 14、场景题-有没有多线程编程的经验
- 15、场景题-缓存设计
1、MySQL-MVCC
是什么?解决什么问题?实现原理?
MVCC是多版本并发控制,是通过记录历史版本数据,解决读写并发冲突问题,避免了读数据时加锁,提高了事务的并发性能
MVCC的实现原理是依靠2个隐藏列、undo log日志、Read View实现的
MySQL将历史数据存储在undo log中,两个隐藏列,一个是事务ID,一个是指向历史数据undo log的指针
事务开启后,执行第一条select语句的时候,会创建ReadView,ReadView记录了当前未提交的事务,通过与历史数据的事务ID比较,可以根据可见性规则进行判断,判断这条记录是否可见,如果可见就直接将这个数据返回给客客户端,如果不可见就继续往undo log版本链查找第一个可见的数据
2、MySQL-原子性怎么实现
undo log
事务的原子性是通过 undo log 实现的,在事务还没提交前,历史数据会记录在 undo log 中,如果事务执行过程中,出现了错误或者用户执行了 ROLLBACK 语句,MySQL 可以利用 undo log 中的历史数据,将数据恢复到事务开始之前的状态,从而保证了事务的原子性。
3、MySQL-持久性怎么实现
redo log
事务的持久性是由 redo log 保证的,因为 MySQL 通过 WAL (先写日志再写数据)机制,在修改数据的时候,会将本次对数据页的修改以 redo log 的形式记录下来,这个时候更新就算完成了,Buffer Pool 的脏页会通过后台线程刷盘,即使在脏页还没刷盘的时候发生了数据库重启,由于修改操作都记录到了 redo log,之前已提交的记录都不会丢失,重启后就通过 redo log,恢复脏页数据,从而保证了事务的持久性。
隔离性怎么实现
MVCC
事务的隔离性是由 MVCC 和锁保证的。
可重复读隔离级别下的快照读(普通select),是通过 MVCC 来保证事务隔离性的
当前读(update、select … for update)是通过锁来保证事务隔离性的。
4、操作系统-死锁产生
当两个或多个进程因竞争资源,而造成互相等待的现象,若无外力推进,则无法推进下去
手写死锁
public class DeadLockDemo {public static void main(String[] args) {final Object objectA = new Object();final Object objectB = new Object();new Thread(() -> {synchronized (objectA) {System.out.println(Thread.currentThread().getName() + "自己持A锁,希望获得B锁");try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }synchronized (objectB) {System.out.println(Thread.currentThread().getName() + "成功获得B锁");}}}, "A").start();new Thread(() -> {synchronized (objectB) {System.out.println(Thread.currentThread().getName() + "自己持B锁,希望获得A锁");try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }synchronized (objectA) {System.out.println(Thread.currentThread().getName() + "成功获得A锁");}}}, "B").start();}
}
死锁排查
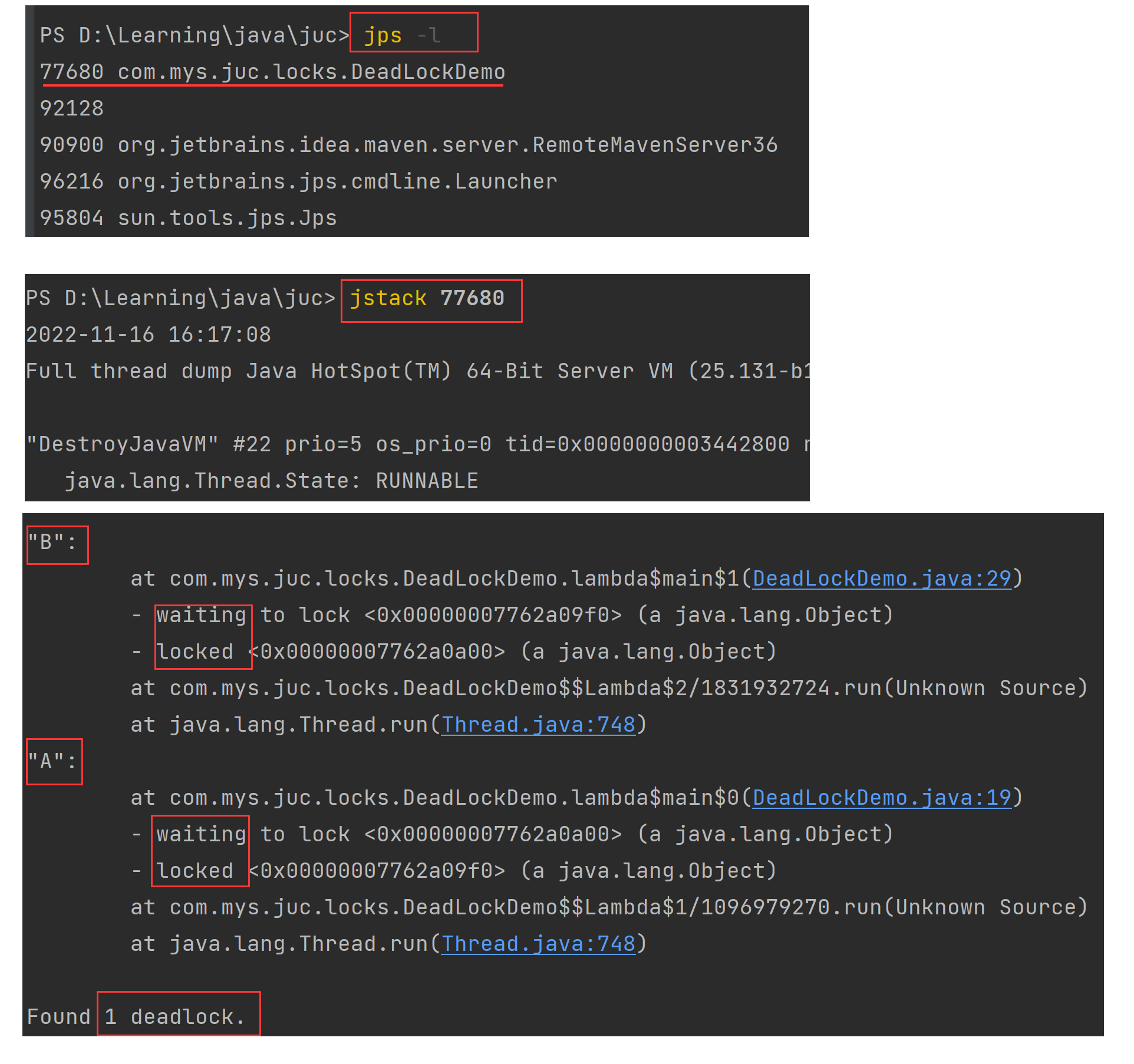
方法一:控制台
jps -l查看端口号,类似linux中的ps -ef|grep xxxjstack 77860查看进程编号的栈信息
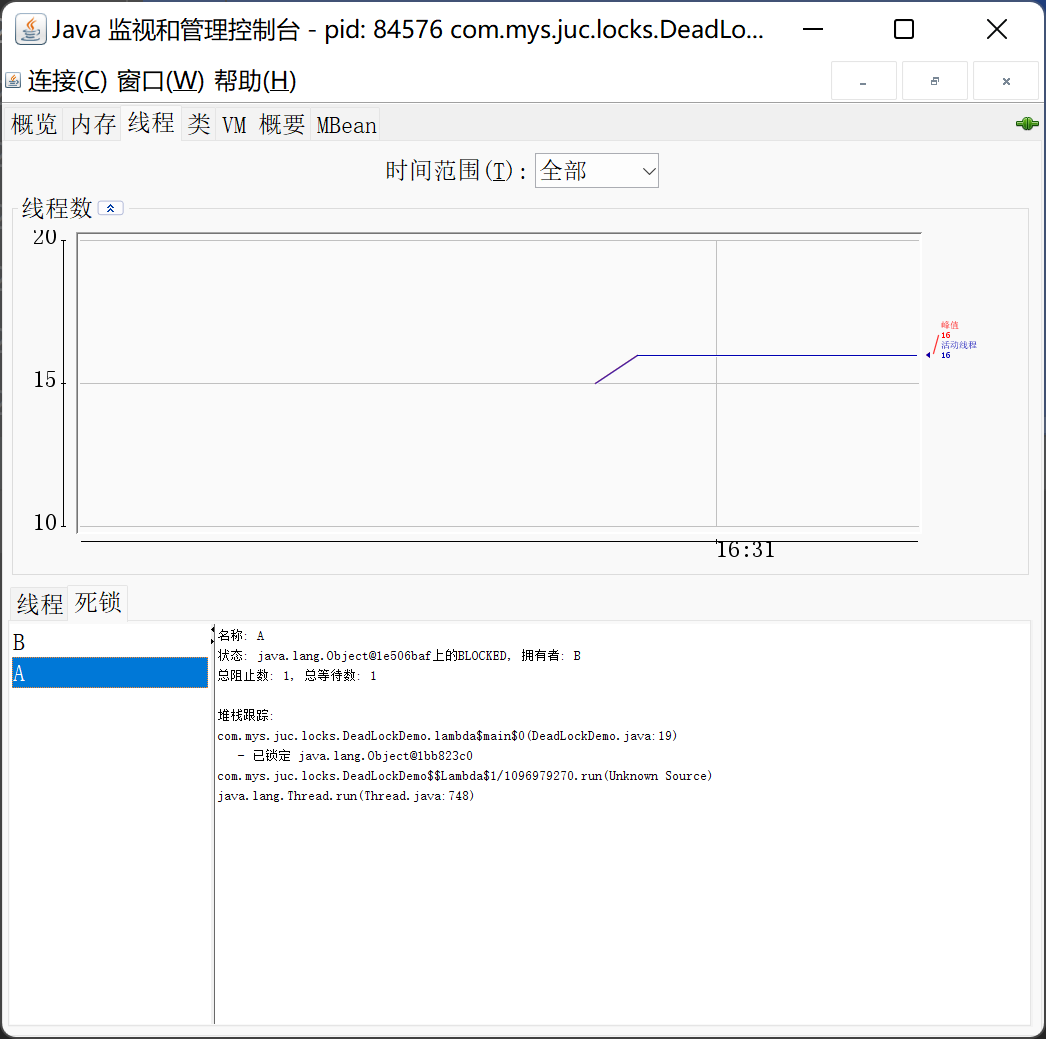
方法二:图形化界面(通用)
win` + `r` 输入`jconsole` ,打开图形化工具,打开`线程` ,点击 `检测死锁
5、操作系统-避免死锁
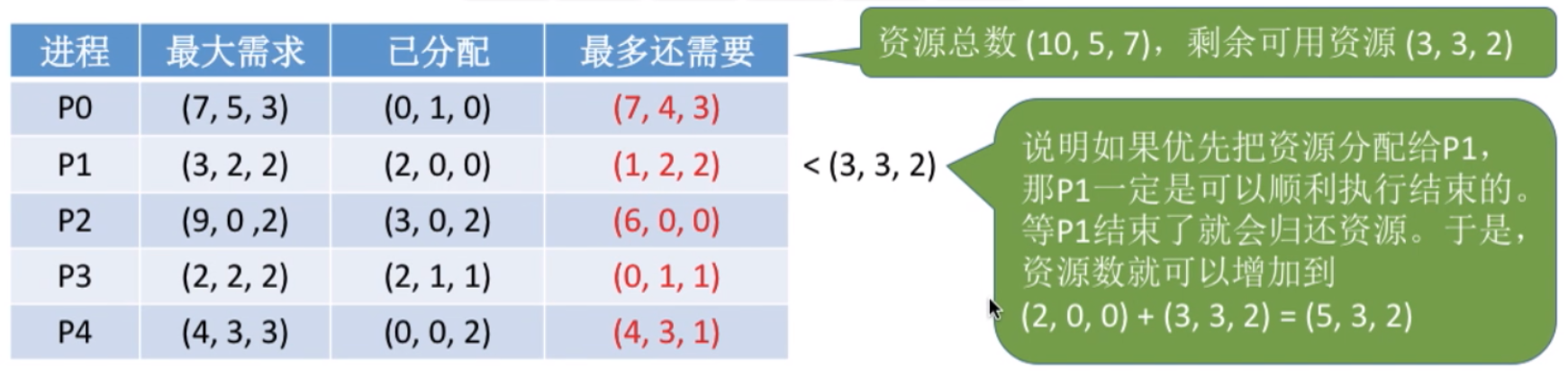
分配资源时,进行预先设计,使用银行家算法保证资源分配在一个安全状态下
安全状态:系统能够按照某种线程推进顺序,为每个线程分配所需资源
安全状态,一定不会发生死锁;不安全状态,可能发生死锁
**银行家算法:在资源分配前,先判断此次分配是否会进入不安全状态,**Dijkstra
死锁的四个必要条件
1、互斥:资源在同一时刻只能被一个线程所占用
2、请求保持:线程对已申请的资源保持不释放
3、不可剥夺:线程获得资源后,未使用完不能被其他线程所剥夺,只有使用完之后主动释放
4、循环等待:若干线程形成一种首尾相接的循环等待的状态
预防死锁
破坏死锁的四个必要条件之一
1、破坏请求与保持条件:一次性申请所有的资源
2、破坏不剥夺条件:如果资源申请不到,可以主动释放已占有的资源
3、破坏循环等待条件:按序申请资源
6、操作系统-pageCache是什么
页缓存,用于缓存文件的页数据,从磁盘中读取到的内容是存储在pageCache里的
零拷贝
详情可参考这篇笔记:https://blog.csdn.net/mys_mys/article/details/131647511?spm=1001.2014.3001.5502
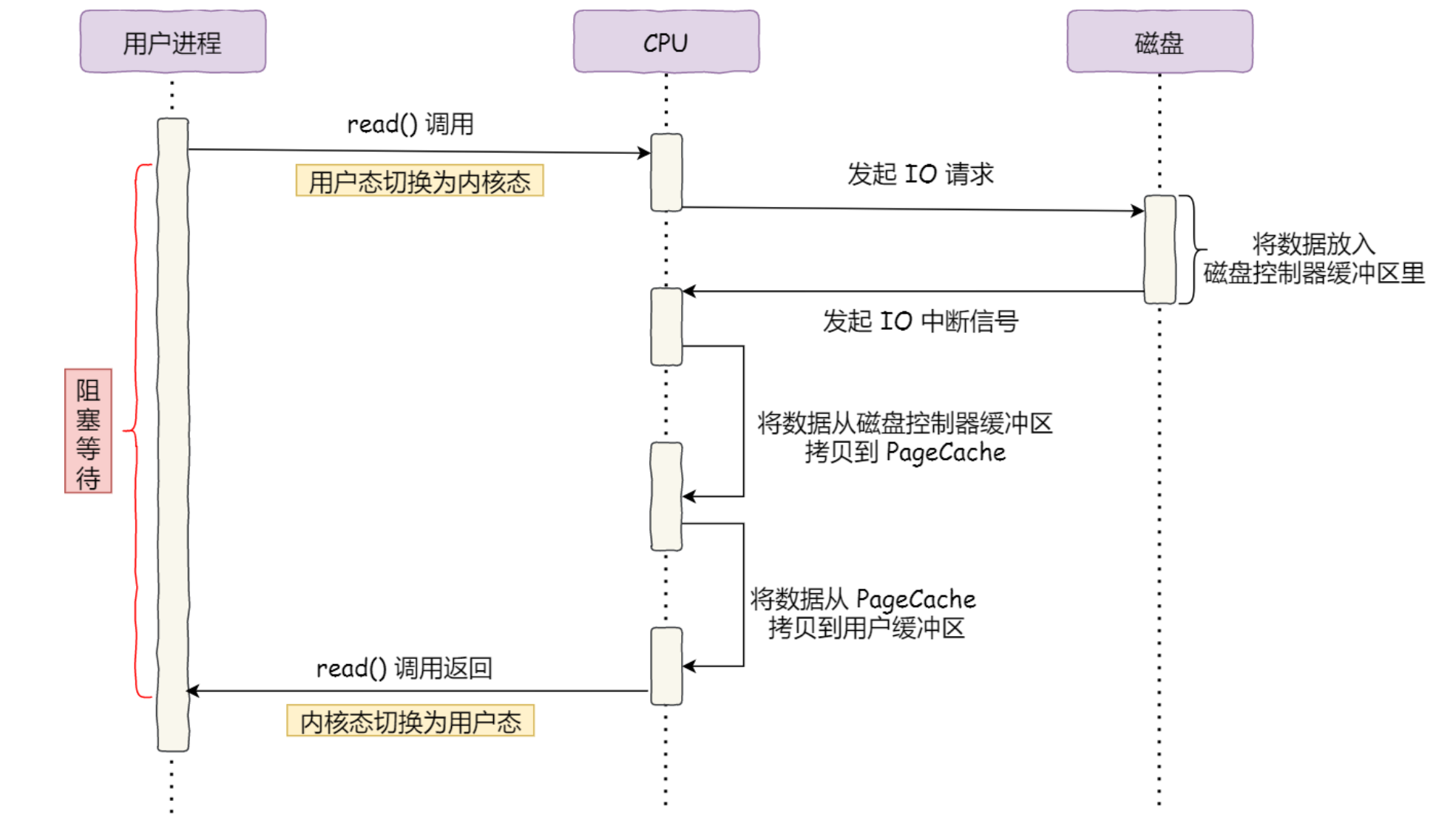
传统IO执行流程
引入DMA
DMA直接内存拷贝,CPU可去处理别的事情
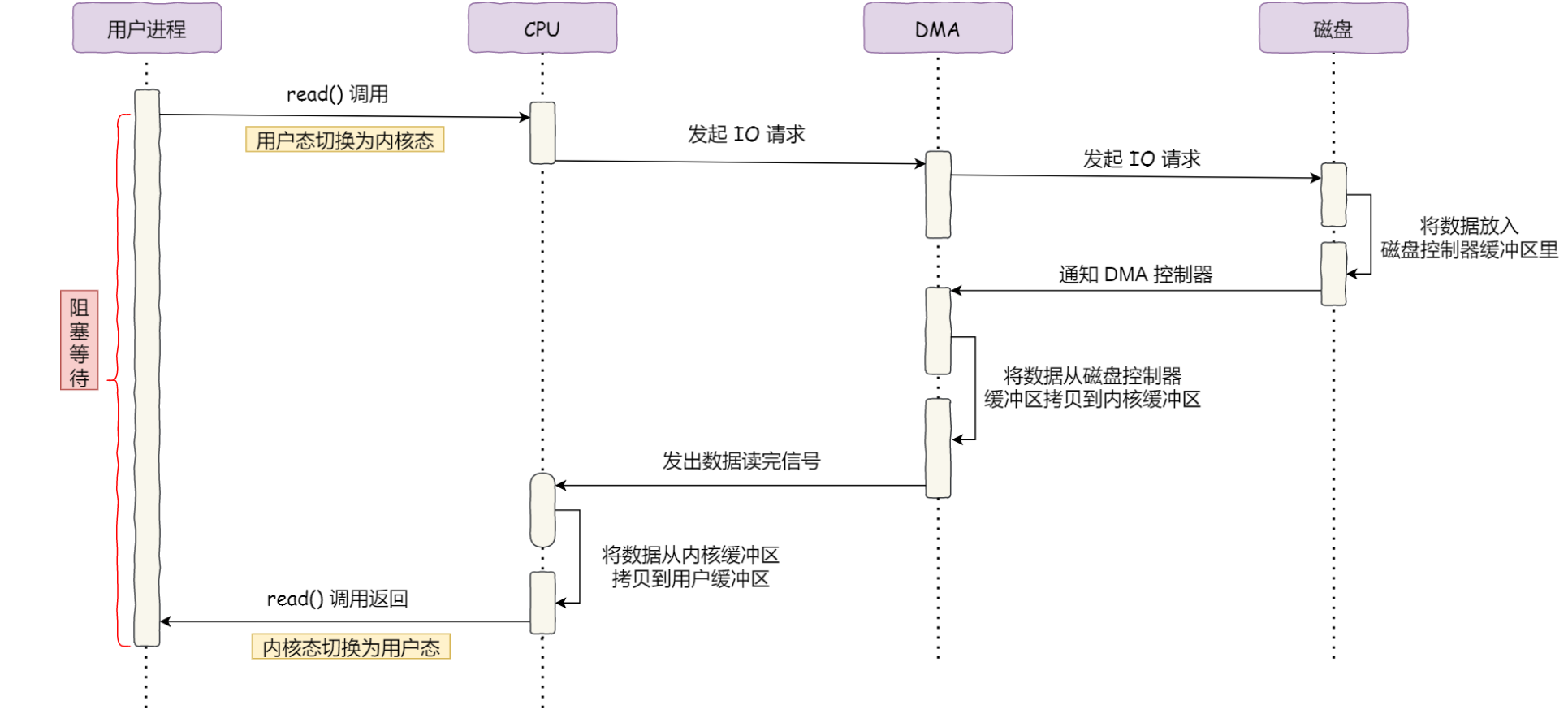
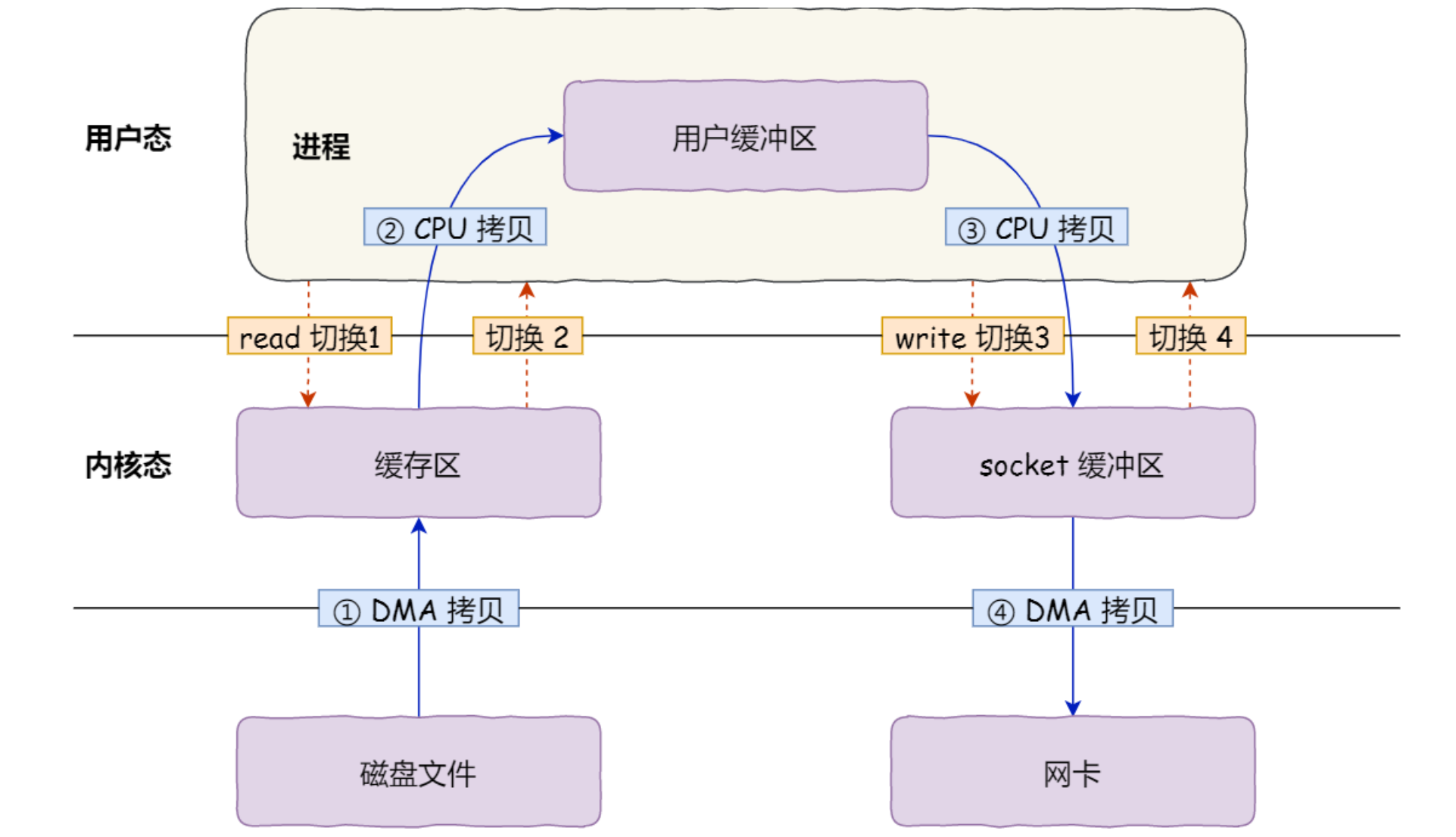
传统文件传输
4次拷贝,4次切换
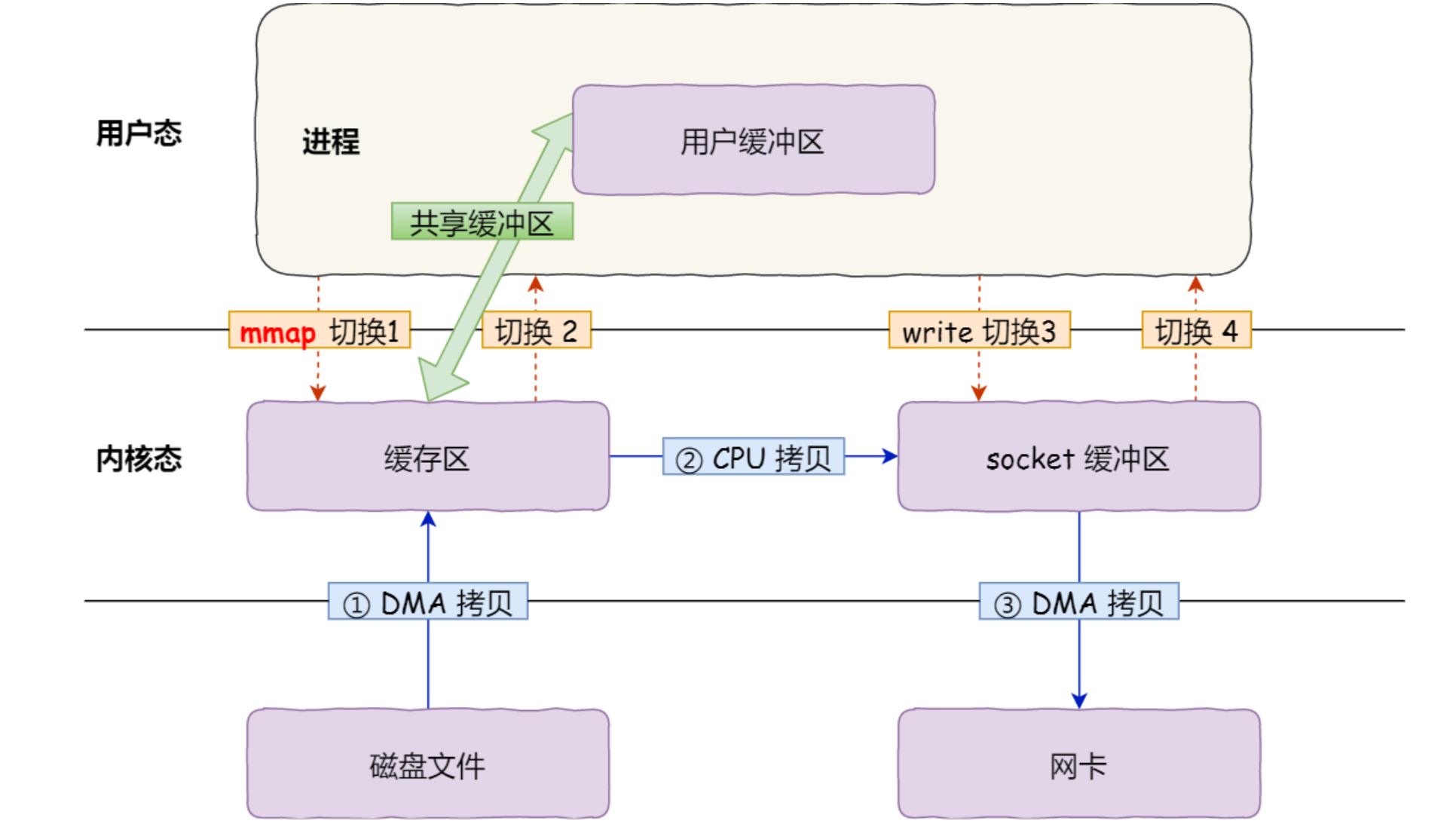
mmap优化
3次拷贝,4次切换
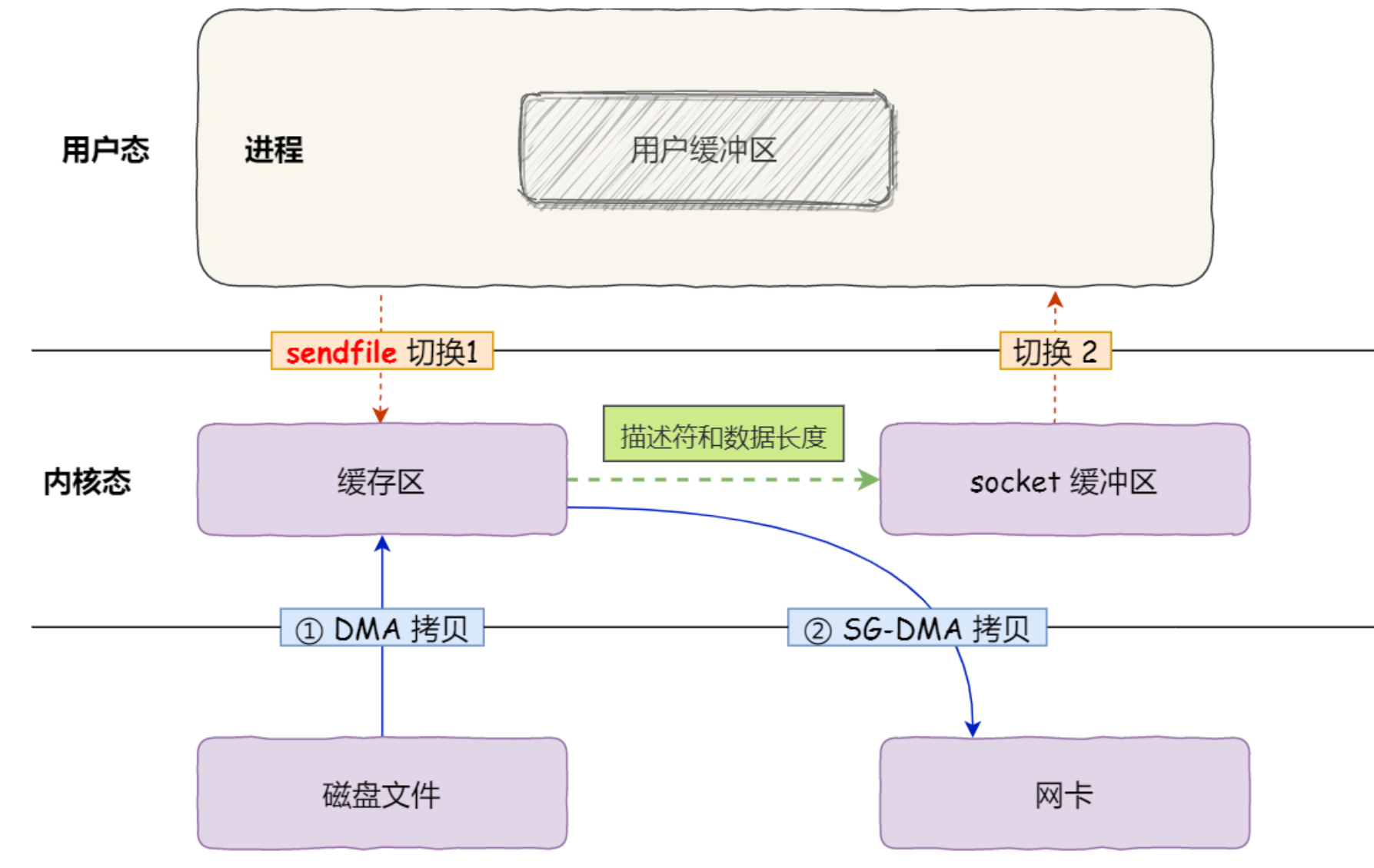
sendFile优化——零拷贝
2次DMA拷贝,2次切换
7、计算机网络-TCP的可靠性和顺序性怎么实现
参考:https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html
1、基于数据块传输
2、对失序数据包重新排序以及去重
3、校验和
4、超时重传
5、流量控制
6、拥塞控制
8、计算机网络-怎么进行流量控制
可以让发送方根据接收方的实际接收能力控制发送的数据量
实现的方式:接收方会有一个接收缓冲区,如果内核接收到了数据,没有被应用读取的话,接收窗口就会收缩,然后会在tcp报文携带接收窗口的大小,发送发收到后,就会控制的发送流量
9、Redis-怎么持久化的数据
Redis持久化是异步进行的,有两种模式,RDB保存快照文件和AOF追加操作日志
RDB模式每隔一段时间会备份一份快照文件,从主进程Fork出一个子进程专门用于持久化,因此恢复速度快,但是容易造成数据丢失;
AOF模式是一种日志模式,记录每条命令的操作日志,重启时通过日志回放进行数据恢复,可以降低数据丢失情况。
RDB和AOF的区别
- 文件类型:RDB生成的是 二进制文件(快照),AOF生成的是 文本文件(追加日志)
- 安全性:缓存宕机时,RDB容易丢失较多的数据,AOF根据策略决定(默认的everysec可以保证最多有一秒的丢失)
- 文件恢复速度:由于RDB是二进制文件,所以恢复速度也比 AOF更快
- 操作的开销:每一次RDB保存都是一次全量保存,操作比较重,通常设置至少5分钟保存一次数据。而AOF的刷盘是一次追加操作,操作比较轻,通常设置策略为每一秒进行一次刷盘
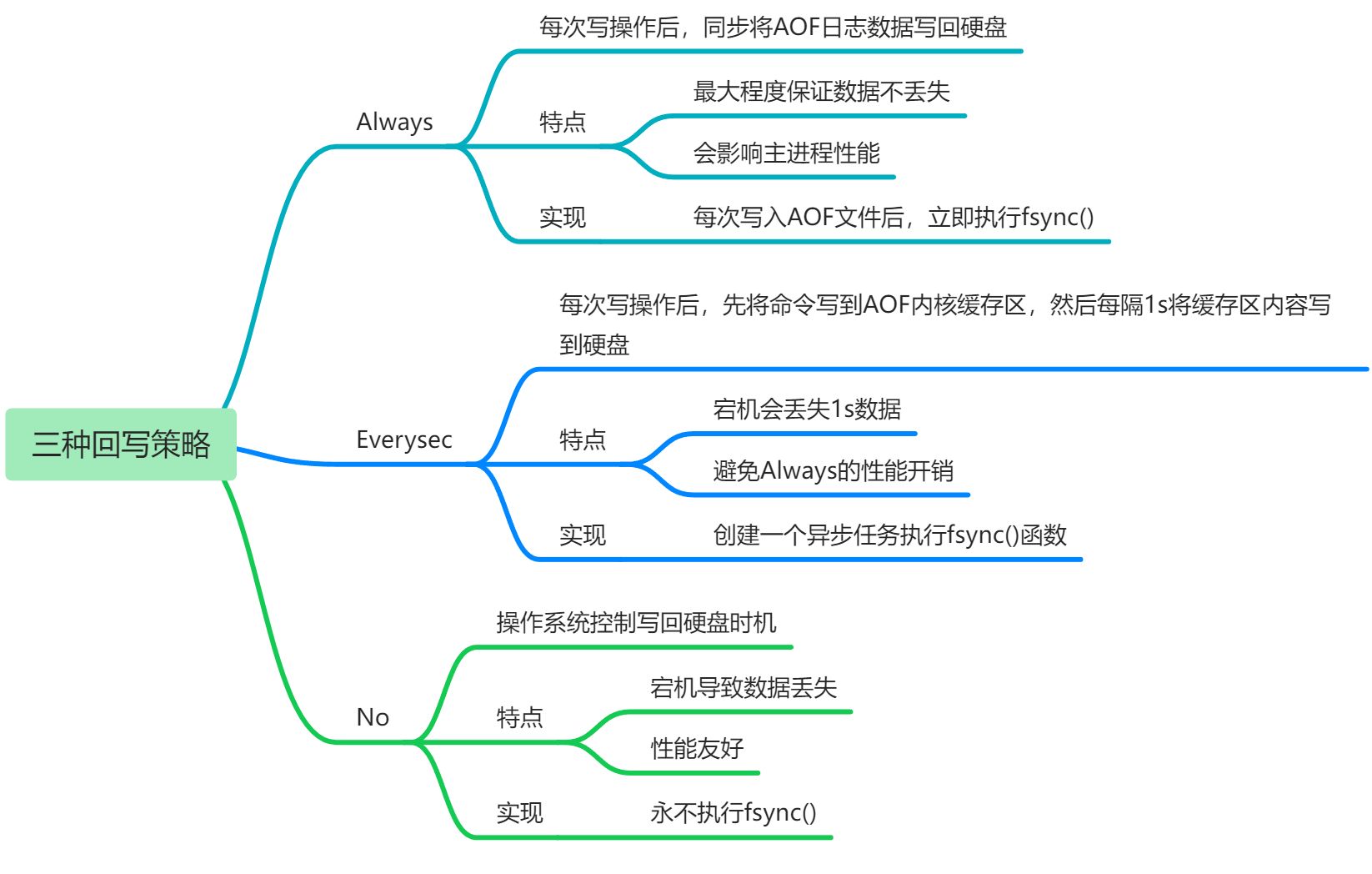
AOF三种回写策略
1、always
2、everysec
3、no
10、Redis-集群是怎么做的?就是数据怎么分片的,然后它的集群的高可用是什么?怎么部署的,这个有没有了解过?
Redis集群
Redis集群中有多个主节点,每个主节点有多个从节点。当主节点发生故障时,从节点被选举为主节点,继续工作;
数据分片
Redis集群使用哈希槽的方式实现数据分片存储,有固定的16384个哈希槽(计算key对应槽位置:CRC16(key)%16384)
流程:客户端连接Redis Cluster中任意一个master节点即可访问Redis Cluster的数据,当客户端发送命令请
求的时候,需要先根据key通过上面的计算公示找到的对应的哈希槽,然后再查询哈希槽和节点的映射关系,即可找到目标节点。
为什么是16384?
假设哈希槽采用 16384,则占空间 2k(16384/8);假设哈希槽采用 65536, 则占空间 8k(65536/8)。并且,Redis Cluster 不太可能扩展到超过 1000 个主节点
所以,65536 个固然可以确保每个主节点有足够的哈希槽,但其占用的空间太大。而且,Redis Cluster 的主节点通常不会扩展太多,16384 个哈希槽完全足够用了
部署
Redis Cluster 至少需要 3 个 master 以及 3 个 slave
slave节点不提供读服务,仅作为备用节点,保障主节点的高可用
Redis Cluster 至少要保证宕机的 master 有一个 slave 可用
11、分布式-分布式事务是什么
先解释什么是分布式事务,解决什么问题?分布式事务的实现方案有哪些?哪个方案比较适合落地?
分布式事务
保证系统中多个相关联的数据库中的数据的一致性
解决方案
2PC、3PC、TCC、本地消息表、MQ 事务(Kafka 和 RocketMQ ) 、Saga
2PC(Two-Phase Commit)
- 2 -> 指代事务提交的 2 个阶段
- P-> Prepare (准备阶段):“询问”事务参与者执行本地数据库事务操作是否成功
- C ->Commit(提交阶段):“询问”事务参与者提交本地事务是否成功
待完善,参考:链接
分布式两大理论
参考:链接
1、CAP理论
- 一致性(Consistence) : 所有节点访问同一份最新的数据副本
- 可用性(Availability): 非故障的节点在合理的时间内返回合理的响应
- 分区容错性(Partition tolerance) : 分布式系统出现网络分区的时候,仍然能够对外提供服务
网络分区:网络出现故障导致某些节点直接不连通,将整个网络分为几个区
先有P,采用C和A——分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构
为了保证 C, 必须要禁止其他节点的读写操作,这就和 A 发生冲突了
为了保证 A,其他节点的读写操作正常的话,那就和 C 发生冲突了
应用:可以作为注册中心的组件有:ZooKeeper、Eureka、Nacos
- ZooKeeper 保证的是 CP
- Eureka 保证的则是 AP
- Nacos 不仅支持 CP 也支持 AP
2、BASE理论
BASE理论是对 CAP 中 AP 方案的一个补充
- Basically Available(基本可用):分布式系统在出现不可预知故障的时,允许损失部分可用性
- Soft-state(软状态) :允许系统中的数据存在中间状态
- Eventually Consistent(最终一致性):系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态
分布式锁
分布式锁需要解决的问题:
可用、死锁、脑裂(两个进程拿到同一个锁)
1、基于MySQL
悲观锁:先查询数据库是否存在记录,通过数据库行锁 select for update 加锁——会一直阻塞直到事务提交
乐观锁:基于MVCC方式实现
首先在数据库增加一个 int 型字段 ver,然后在 SELECT 同时获取 ver 值,最后在 UPDATE 的时候检查 ver 值是否为与第 2 步或得到的版本值相同
2、基于Redis——性能
(1)Redis的Set命令和Lua脚本
// 加锁
SET key value NX PX 10000
// NX:key不存在时才设置
// PX:过期时间// 解锁
// 使用Lua脚本,保证解锁操作的原子性
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])
elsereturn 0
end
**(2)**Redission
解决 Redis 集群节点实现分布式锁的问题
// 1.获取指定的分布式锁对象
RLock lock = redisson.getLock("lock");
// 2.拿锁且不设置锁超时时间,具备 Watch Dog 自动续期机制
lock.lock();
// 3.执行业务
...
// 4.释放锁
lock.unlock();
只有未指定锁超时时间,才会使用到 Watch Dog 自动续期机制
// 手动给锁设置过期时间,不具备 Watch Dog 自动续期机制
lock.lock(10, TimeUnit.SECONDS);
自动续期机制Watch Dog
操作共享资源的线程还未执行完成的话,Watch Dog 会不断地延长锁的过期时间,进而保证锁不会因为超时而被释放
3、基于Zookeeper——可靠性
ZooKeeper 分布式锁是基于 临时顺序节点 和 Watcher(事件监听器) 实现的
推荐使用 Curator 来实现 ZooKeeper 分布式锁
- InterProcessMutex:分布式可重入排它锁
- InterProcessSemaphoreMutex:分布式不可重入排它锁
- InterProcessReadWriteLock:分布式读写锁
- InterProcessMultiLock:将多个锁作为单个实体管理的容器,获取锁的时候获取所有锁,释放锁也会释放所有锁资源(忽略释放失败的锁)
CuratorFramework client = ZKUtils.getClient();
client.start();
// 分布式可重入排它锁
InterProcessLock lock1 = new InterProcessMutex(client, lockPath1);
// 分布式不可重入排它锁
InterProcessLock lock2 = new InterProcessSemaphoreMutex(client, lockPath2);
// 将多个锁作为一个整体
InterProcessMultiLock lock = new InterProcessMultiLock(Arrays.asList(lock1, lock2));if (!lock.acquire(10, TimeUnit.SECONDS)) {throw new IllegalStateException("不能获取多锁");
}
System.out.println("已获取多锁");
System.out.println("是否有第一个锁: " + lock1.isAcquiredInThisProcess());
System.out.println("是否有第二个锁: " + lock2.isAcquiredInThisProcess());
try {// 资源操作resource.use();
} finally {System.out.println("释放多个锁");lock.release();
}
System.out.println("是否有第一个锁: " + lock1.isAcquiredInThisProcess());
System.out.println("是否有第二个锁: " + lock2.isAcquiredInThisProcess());
client.close();
4、基于etcd
12、分布式-paxos和raft的区别
Paxos在一个节点当选为就是 leader 节点之后,其他的从节点如果不满主节点的那个投票策略的话,是可以对主节点的投票就是进行否决的。Paxos就是三阶段提交。
raft 的话就是只要集群中存在 leader 节点的话,从节点就是会按照主节点的策略来进行一致性的执行
13、分布式-为什么就是分布式的共识算法都需要要求多数派提交才能完成它的分布式一致性?
14、场景题-有没有多线程编程的经验
https://mp.weixin.qq.com/s/BE9lti3pJ1H8HveUUXCFgQ
利用线程池,批量拉取任务
比如一次拉取500个任务,这时候可以直接开500个线程,但为了资源复用,可以引入线程池技术
// 1.创建线程池
ThreadPoolExecutor threadPoolExecutor; // 拉取任务的线程池
// ThreadPoolExecutor参数:
// corePoolSize 核心线程数
// maximumPoolSize 最大线程数
// keepAliveTime 超出核心线程数的线程存活时间
// TimeUnit unit keepAliveTime单位
// BlockingQueue<Runnable> workQueue 工作队列,存放待处理的任务
this.threadPoolExecutor = new ThreadPoolExecutor(concurrentRunTimes, MaxConcurrentRunTimes, intervalTime + 1, TimeUnit.SECONDS, new LinkedBlockingQueue<>(UserConfig.QUEUE_SIZE));// 2.判断是否满足执行条件
// 线程池等待队列:总数-已拉取任务数(剩余位置)>=一次拉取多少个任务
if (UserConfig.QUEUE_SIZE - threadPoolExecutor.getQueue().size() >= scheduleLimit) {execute(taskType);
}
// 3.执行任务
threadPoolExecutor.execute(() -> executeTask(asyncTaskBaseList, finalI));
15、场景题-缓存设计
class LRUCache {//创建一个双链表节点class node{int key, value;node left, right;public node(int key, int value) {this.key = key;this.value = value;left = null;right = null;}}//全局变量node L, R;int n;Map<Integer, node> hash = new HashMap<>();//初始化双链表public LRUCache(int capacity) {n = capacity;L = new node(-1, -1);R = new node(-1, -1);L.right = R;R.left = L;}public int get(int key) {//判断key是否存在哈希表中,不存在:返回-1,存在:从该位置删除后插入到链表最左端,并返回其值//(保证链表越往左越旧,越往右越新;如果超过缓存,就删除最右边的)if (! hash.containsKey(key)) {//不存在return -1;}node p = hash.get(key);//使用时间改变,通过位置变动来实现remove(p);//从该位置删除insert(p);//插入到最左端return p.value;}public void put(int key, int value) {//判断key是否存在哈希表中if (hash.containsKey(key)) {//存在,不需要插入,修改值即可。找到p并修改value和使用时间(也就是位置变动)node p = hash.get(key);//找到pp.value = value;//修改value//修改位置remove(p);insert(p);} else {//不存在,需要插入//先判断哈希表是否已满if (hash.size() == n) {//已满,则需要先删除最长未使用的节点后再插入(即链表最右边的点)node p = R.left;//找到最右边节点并删除remove(p);hash.remove(p.key);//注意:不仅要删除双链表中的节点,还要删除哈希表中的节点}//先创建节点node p = new node(key, value);//插入hash.put(key, p);insert(p);}}//删除p节点void remove(node p) {p.right.left = p.left;p.left.right = p.right;}//插入节点:插到最左侧void insert(node p) {p.right = L.right;p.left = L;L.right.left = p;L.right = p;}public static void main(String[] args) {//["LRUCache","put","put","get","put","get","put","get","get","get"]//[[2],[1,0],[2,2],[1],[3,3],[2],[4,4],[1],[3],[4]]LRUCache obj = new LRUCache(2);obj.put(1, 0);obj.put(2, 2);System.out.println(obj.get(1));obj.put(3, 3);System.out.println(obj.get(2));obj.put(4, 4);System.out.println(obj.get(1));System.out.println(obj.get(3));System.out.println(obj.get(4));}
}