网站建设带主机安徽seo优化
0x0 背景
相信大家都使用或者听说过github copilot这个高效的代码生成工具。CodeGeeX类似于github copilot,是由清华大学,北京智源研究院,智谱AI等机构共同开发的一个拥有130亿参数的多编程语言代码生成预训练模型。它在vscode上也提供了插件,可以直接安装使用,我个人体验了一下代码生成的功能还不错。此外除了代码生成,CodeGeeX还可以做代码加注释,不同语言翻译(比如把c++代码翻译为python)等,感兴趣的读者可以体验一下。并且可以在 https://models.aminer.cn/codegeex/blog/index_zh.html 这个官方博客上查看更多详细信息。
为了说明oneflow在大模型训练和推理上的高效性,继上次对glm10b模型的训练优化工作 之后,我们对CodeGeeX模型的推理进行优化。在oneflow团队的优化下,CodeGeeX可以使用oneflow的后端进行推理并且在FP16和INT8模式的推理速度均可以超过CodeGeeX团队基于FasterTransformer的方案(基于NVIDIA A100显卡进行测试)。oneflow的推理方案已经upstream CodeGeeX的主分支,欢迎小伙伴查看。需要指出的是本文用到的大多数cuda优化手段均由oneflow的柳俊丞大佬提供,在此致敬。本着开源精神,本文将展示一下我们的优化结果并且解析一下我们的优化手段,和大家共同探讨学习。介于篇幅原因,在解析优化手段时,我们会简单介绍一下优化的原理并给出代码链接。但不会详细阅读优化涉及到的cuda kernel,感兴趣的小伙伴可以留言,后续我再推出更详细的解读。
- CodeGeeX代码链接:https://github.com/THUDM/CodeGeeX (点击右下角BBuf的头像就可以找到oneflow的pr)
- OneFlow代码链接:https://github.com/Oneflow-Inc/oneflow
0x1. 优化后的结果
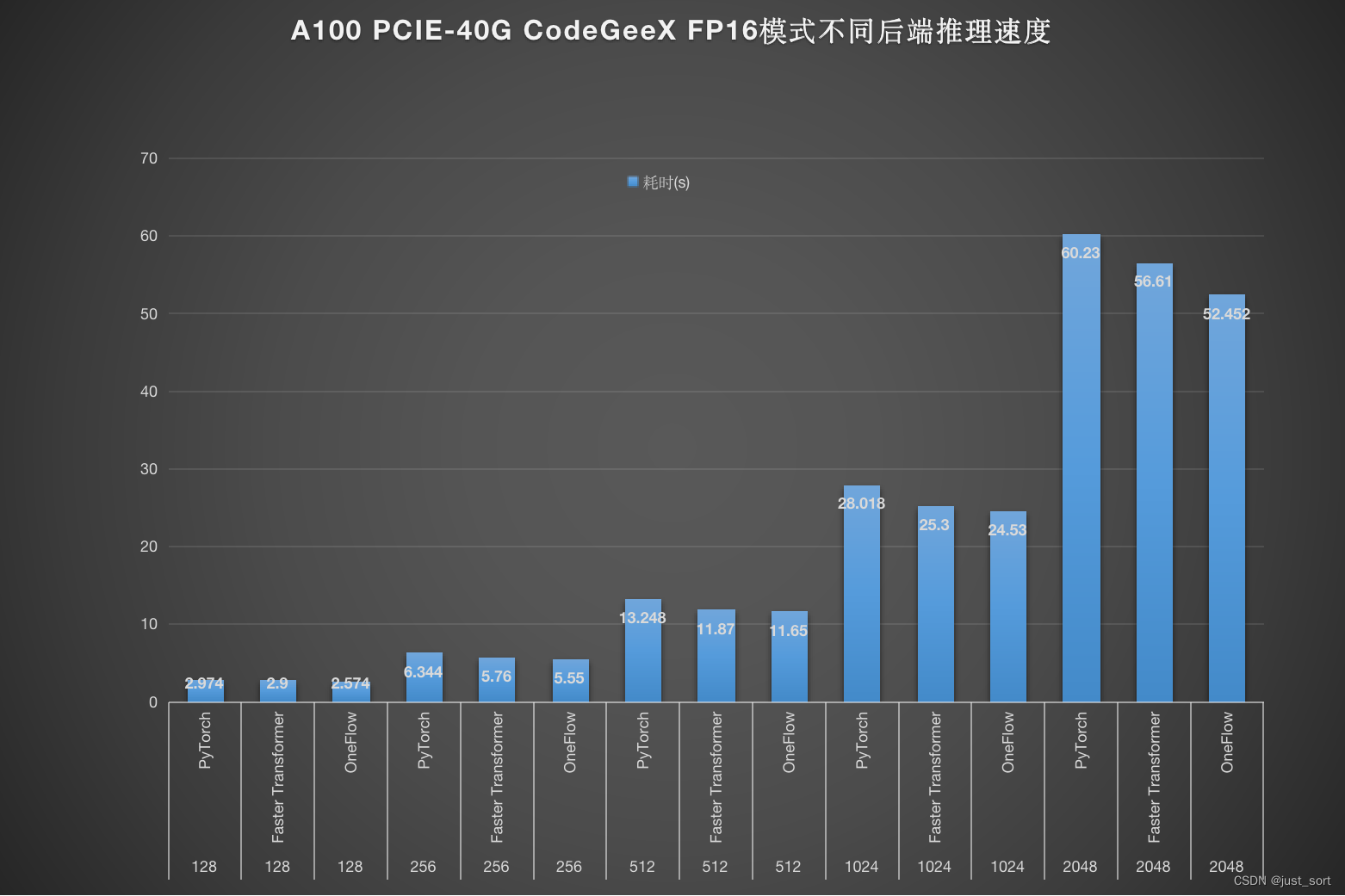
我们在A100 PCIE-40G上对比了分别使用PyTorch,FasterTransformer以及Oneflow推理CodeGeeX模型的耗时情况,FP16模式推理速度结果如下:
 INT8模式的推理速度如下:
INT8模式的推理速度如下:
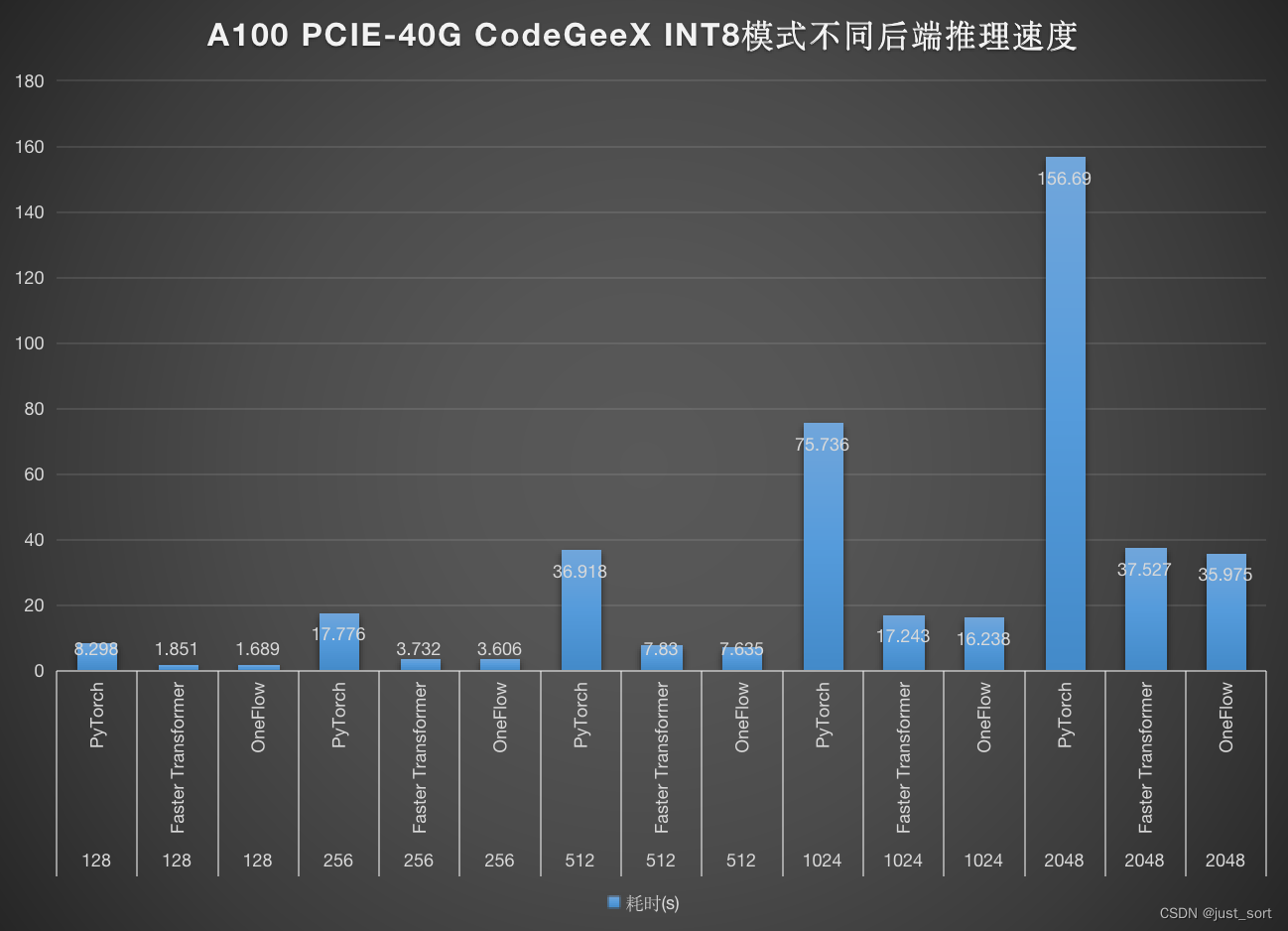
可以看到无论是在FP16模式还是INT8模式,OneFlow均取得了最好的性能结果。也许有些读者会提出似一个疑问,似乎OneFlow的性能并没有超越FasterTransformer太多,选择OneFlow的好处是?我个人认为由于C++以及手动插入集合通信的原因FasterTransformer的适配难度是相对比较大的,特别是多卡模式,而OneFlow不仅拥有和PyTorch一模一样的用户体验并且扩展到多卡时不需要用户手动管理集合通信的问题,用户体验拉满。
除了性能优势,OneFlow也可以节省一些显存资源消耗,详细的信息可以点击这个链接查看:https://github.com/THUDM/CodeGeeX/pull/87 。
0x2. 优化手段解析
针对CodeGeeX大模型的推理,OneFlow做了什么优化可以超越NVIDIA FasterTransformer库的推理速度呢?
- quick_gelu融合优化。https://github.com/THUDM/CodeGeeX/blob/main/codegeex/oneflow/codegeex_model.py#L7-L11 指的是将
x / (1 + torch.exp(-1.702 * torch.abs(x))) * torch.exp(0.851 * (x - torch.abs(x)))这个elementwise操作组合成的pattern融合成一个算子,在oneflow中为flow._C.quick_gelu。 - grouped_matmul_bias优化。https://github.com/THUDM/CodeGeeX/blob/main/codegeex/oneflow/codegeex_model.py#L101-L108 指的是将一堆同时执行并且数据没有前后依赖关系的matmul+bias_add算子融合成一个cuda kernel,降低kernel launch的开销。https://github.com/Oneflow-Inc/oneflow/pull/9413。
- 更高效的fused attention kernel(在oneflow中使用
flow._C.fused_multi_head_attention_inference_v2调用)。在oneflow中引入了cutlass的fmha以及TensorRT的FlashAttention实现,可以在不同的数据规模调用最优的fmha实现。在此基础上oneflow针对Q,K,V可能存在的不同数据排布进行优化,具体来说oneflow的fused_multi_head_attention_inference_v2接口支持手动配置Q,K,V这三个输入tensor的数据排布。比如在CodeGeeX里面,Q,K,V的shape是[seq_lenght, batch_size, num_heads * hidden_size_per_attention_head],我们就可以直接把Q,K,V的数据排布配置成MB(HK),并且输出的数据排布也配置成MB(HK),这样就可以避免在把Q,K,V传入fused_multi_head_attention_inference_v2之前需要额外做的reshape带来的开销了,同样输出Tensor的reshape开销也可以避免。https://github.com/THUDM/CodeGeeX/blob/main/codegeex/oneflow/codegeex_model.py#L253-L264 。这部分的cuda实现分成很多pr,这里指一下路:https://github.com/Oneflow-Inc/oneflow/pull/9950 & https://github.com/Oneflow-Inc/oneflow/pull/9933。 - CodeGeeX和大多数的自回归模型一样有一个增量推理阶段,需要把当前的key,value和上一轮的key,value concat起来,也就是:https://github.com/THUDM/CodeGeeX/blob/main/codegeex/oneflow/codegeex_model.py#L135-L140 。针对这个特殊的操作,我们也开发了一个可以配置输入输出数据排布的fuse kernel,把两个concat操作融合起来降低kernel launch以及reshape的开销。https://github.com/THUDM/CodeGeeX/blob/main/codegeex/oneflow/codegeex_model.py#L239 。在oneflow中对应https://github.com/Oneflow-Inc/oneflow/pull/9963 。
- fused matmul+bias。https://github.com/THUDM/CodeGeeX/blob/main/tests/test_inference_oneflow.py#L14 。具体来说就是将Linear中的matmul和bias_add融合在一起。https://github.com/Oneflow-Inc/oneflow/pull/9369。
上述优化既适用于FP16模式,也适用于INT8模式,接下来我们聊一下INT8 weight only quantization的motivation以及优化。经过调研,FasterTransformer的INT8模式采用了weight only quantization的方式,也就是只对Linear层的权重进行量化,但是在计算的时候仍然要反量化回FP16和Activation进行矩阵乘计算。按道理来说,加入了反量化之后速度应该变慢才对,为什么这里使用了INT8 weight quantization之后反而能加速最终的推理速度呢?这是因为在这个网络中,推理时的batch_size以及seq_length都是1,这个时候的矩阵乘法退化到了一个向量和一个矩阵相乘的情况,实际上类似于卷积神经网络中的全连接层,是一个典型的访存密集型算子。所以这里对weight进行反量化和矩阵乘法可以fuse到一起来进行加速(原因是减少了访存)。在oneflow中的实现对应:https://github.com/Oneflow-Inc/oneflow/pull/9900 。然后我基于这个算子在CodeGeeX中实现了OneFlow INT8版本的推理脚本:https://github.com/THUDM/CodeGeeX/blob/main/codegeex/quantization/quantize_oneflow.py
0x3. 总结
至此,我分享完了我们团队最近加速CodeGeeX百亿参数大模型推理的所有优化技巧,相信对要做LLM大模型的推理的小伙伴会有帮助。本着开源精神,请给oneflow点击star再研究相关优化。此外,更多的优化解读我也会放到个人仓库:https://github.com/BBuf/how-to-optim-algorithm-in-cuda ,欢迎大家关注。