百度收录效果好的网站刷粉网站推广
前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
正文
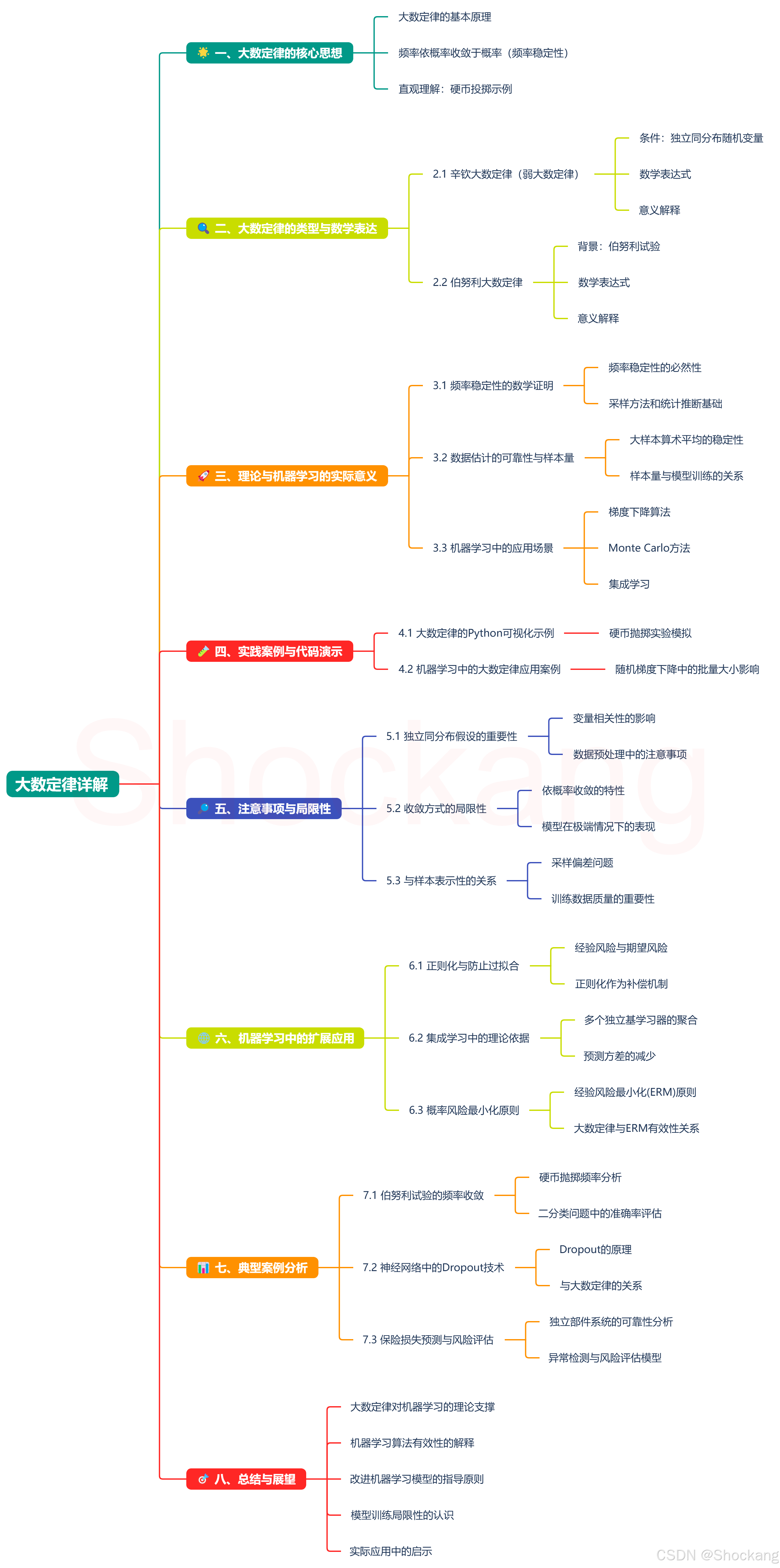
🌟 一、大数定律的核心思想
大数定律(Law of Large Numbers)揭示了一个基本真理:当大量独立同分布随机变量通过算术平均组合时,其平均值会稳定收敛于理论期望值。这一定律从数学上严格证明了统计学中的经验事实:频率依概率收敛于概率(即频率稳定性)。
💡 直观理解:投掷硬币次数越多,出现正面的频率越接近理论概率0.5
🔍 二、大数定律的类型与数学表达
2.1 辛钦大数定律(弱大数定律)
- 条件:随机变量序列 X 1 , X 2 , … , X n X_1, X_2, \dots, X_n X1,X2,…,Xn 独立同分布(i.i.d.),且数学期望 E ( X k ) = μ E(X_k) = \mu E(Xk)=μ 存在。
- 结论:对于任意 ϵ > 0 \epsilon > 0 ϵ>0,有
lim n → ∞ P ( ∣ 1 n ∑ k = 1 n X k − μ ∣ < ϵ ) = 1 \lim_{n \to \infty} P\left( \left| \frac{1}{n} \sum_{k=1}^n X_k - \mu \right| < \epsilon \right) = 1 limn→∞P( n1∑k=1nXk−μ <ϵ)=1 - 意义:随着观测次数 n n n 增大,样本均值 1 n ∑ X k \frac{1}{n} \sum X_k n1∑Xk 与真实期望 μ \mu μ 的偏差超过任意小正数 ϵ \epsilon ϵ 的概率趋近于零。
2.2 伯努利大数定律
- 背景:n 次独立伯努利试验(例如抛硬币),事件 A 发生的次数为 f A f_A fA,单次概率为 p p p。
- 结论:对于任意 ϵ > 0 \epsilon > 0 ϵ>0,有
lim n → ∞ P ( ∣ f A n − p ∣ < ϵ ) = 1 \lim_{n \to \infty} P\left( \left| \frac{f_A}{n} - p \right| < \epsilon \right) = 1 limn→∞P( nfA−p <ϵ)=1 - 意义:试验次数足够多时,事件发生的频率 f A n \frac{f_A}{n} nfA 几乎必然接近真实概率 p p p,这是概率定义的客观基础。
🚀 三、理论与机器学习的实际意义
3.1 频率稳定性的数学证明
- 实际中观察到的频率稳定性(如抛硬币正面占比趋近 50%)不是偶然现象,而是大数定律的必然结果。
- 在机器学习中,这为采样方法和统计推断提供了理论基础。
3.2 数据估计的可靠性与样本量
- 通过大样本的算术平均估计期望值(如估计平均收入、产品合格率等),结果具有强稳定性。
- 机器学习应用:数据量过小时,模型训练结果的不确定性较大;随着样本量增大,参数估计逐渐稳定,模型性能趋于一致。
3.3 机器学习中的应用场景
- 梯度下降算法:随机梯度下降(SGD)方法中,随机采样的梯度虽有波动,但平均来看会收敛到真实梯度,这正是大数定律的应用。
- Monte Carlo方法:通过大量随机采样近似计算复杂积分,广泛应用于强化学习和贝叶斯推断。
- 集成学习:多个独立弱学习器的预测结果聚合,可以提高整体预测性能,这背后也是大数定律在起作用。
🧪 四、实践案例与代码演示
4.1 大数定律的Python可视化示例
import numpy as np
import matplotlib.pyplot as plt# 模拟抛硬币实验
np.random.seed(42) # 设置随机种子
n_flips = 10000 # 抛掷次数
p_true = 0.5 # 真实概率# 生成随机实验结果(1代表正面,0代表反面)
flips = np.random.binomial(1, p_true, n_flips)# 计算累积平均值
cumulative_means = np.cumsum(flips) / np.arange(1, n_flips+1)# 可视化结果
plt.figure(figsize=(10, 6))
plt.plot(range(1, n_flips+1), cumulative_means, label='观测频率')
plt.axhline(y=p_true, color='r', linestyle='-', label='真实概率')
plt.xscale('log') # 对x轴使用对数刻度以便观察
plt.xlabel('抛掷次数')
plt.ylabel('正面频率')
plt.title('大数定律演示:硬币抛掷实验')
plt.legend()
plt.grid(True)
plt.show()
这段代码模拟了抛硬币实验并展示了随着试验次数增加,观测频率如何越来越接近理论概率。
4.2 机器学习中的大数定律应用案例
案例一:随机梯度下降中的批量大小影响
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import SGDRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 生成回归数据集
X, y = make_regression(n_samples=10000, n_features=1, noise=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 不同批量大小的SGD
batch_sizes = [1, 10, 100, 1000]
epochs = 50
results = {}for batch_size in batch_sizes:# 初始化模型sgd = SGDRegressor(max_iter=1, learning_rate='constant', eta0=0.01, random_state=42)test_errors = []for _ in range(epochs):# 模拟一次迭代indices = np.random.choice(len(X_train), batch_size)sgd.partial_fit(X_train[indices], y_train[indices])# 计算测试误差y_pred = sgd.predict(X_test)mse = mean_squared_error(y_test, y_pred)test_errors.append(mse)results[batch_size] = test_errors# 可视化结果
plt.figure(figsize=(10, 6))
for batch_size, errors in results.items():plt.plot(range(1, epochs+1), errors, label=f'批量大小={batch_size}')plt.xlabel('迭代次数')
plt.ylabel('测试MSE')
plt.title('不同批量大小对SGD收敛的影响')
plt.legend()
plt.grid(True)
plt.show()
这个例子展示了随机梯度下降中,较大批量大小通常会带来更平滑的收敛曲线,这是因为大数定律使得大批量的平均梯度更接近真实梯度。
🔎 五、注意事项与局限性
5.1 独立同分布假设的重要性
- 若变量间存在强相关性或分布不一致,大数定律可能不成立。
- 机器学习启示:数据预处理时应注意特征间的相关性和数据分布,尤其是时间序列数据等非独立同分布数据。
5.2 收敛方式的局限性
- 大数定律是依概率收敛(而非逐点收敛),即允许小概率的极端偏离,但随着 n n n 增大,偏离的可能性逐渐减小。
- 机器学习启示:模型虽然整体表现良好,但仍可能在少数极端情况下表现失常。
5.3 与样本表示性的关系
- 大数定律要求样本能代表总体,在实际应用中需警惕采样偏差问题。
- 机器学习启示:训练数据的采集方式和质量对模型的最终性能至关重要,需避免数据偏差导致的"垃圾进垃圾出"。
🌐 六、机器学习中的扩展应用
6.1 正则化与防止过拟合
大数定律告诉我们,当观测数据足够多时,经验风险会逐渐接近期望风险。然而,在实际的机器学习任务中,我们往往面临有限的训练样本。正则化可以视为一种补偿机制,当数据不足以让经验风险稳定接近期望风险时,通过引入先验信息来稳定模型表现。
6.2 集成学习中的理论依据
集成学习(如随机森林、Boosting等)的成功很大程度上归功于大数定律。当我们训练多个独立的基学习器并聚合它们的预测结果时,可以显著减少预测方差,从而提高整体模型的稳定性和准确性。
6.3 概率风险最小化原则
在统计学习框架下,机器学习的目标是寻找使期望风险最小的决策函数。由于真实分布未知,我们只能通过经验风险近似。大数定律保证了当样本量足够大时,这种近似是合理的,这也是ERM(经验风险最小化)原则有效性的理论基础。
📊 七、典型案例分析
7.1 伯努利试验的频率收敛
- 重复抛硬币试验中,正面频率 f A n \frac{f_A}{n} nfA 随 n n n 增大逼近真实概率 p p p。
- 机器学习实例:二分类问题中的准确率评估通常需要足够多的测试样本才有统计意义。
7.2 神经网络中的Dropout技术
Dropout是一种防止过拟合的正则化技术,其工作原理可以从大数定律角度理解:通过随机关闭部分神经元,相当于训练了多个不同网络结构的模型,最终结果近似于这些模型的集成,提高了泛化能力。
7.3 保险损失预测与风险评估
- 系统由 100 个独立部件组成,每个损坏概率 0.1,通过大数定律计算系统正常工作的概率(至少 85 个正常)。
- 应用中心极限定理(正态近似)得 P ( 正常部件 ≥ 85 ) P(\text{正常部件} \geq 85) P(正常部件≥85) 的具体值。
- 机器学习扩展:异常检测、风险评估模型同样基于类似概率原理构建。
🎯 八、总结与展望
大数定律作为概率论与统计学的基本定理,为机器学习的众多理论与方法奠定了坚实基础:
- 它解释了为什么机器学习算法能够工作:大样本下的统计推断具有可靠性
- 它指导了如何改进机器学习模型:增加训练样本、采用集成方法、调整批量大小等
- 它揭示了模型训练的局限性:数据质量与代表性的重要性
在实际应用中,理解大数定律的本质,能够帮助我们设计更加健壮的机器学习系统,避免常见陷阱,并对模型性能和可靠性有更为深刻的洞察。