培训网站开发需求说明书推广普通话图片
目录
机器学习概念
基本术语-数据
基本术语-任务
基本术语-泛化能力
样本空间、假设空间、版本空间
样本空间:
假设空间:
版本空间:
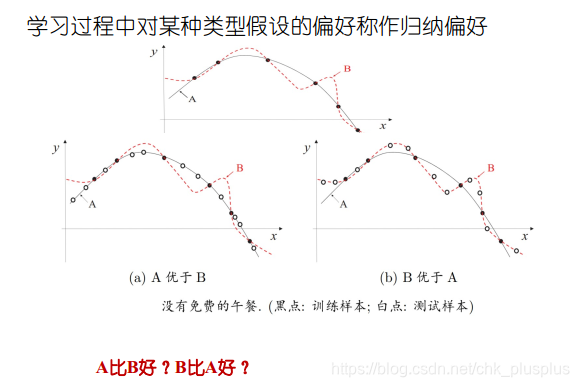
归纳偏好
没有免费午餐定理(NFL)
机器学习概念

基本术语-数据
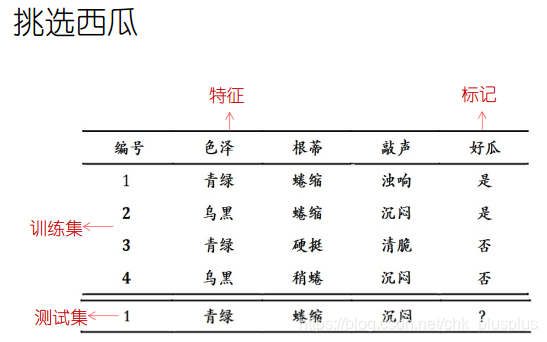
基本术语-任务

基本术语-泛化能力
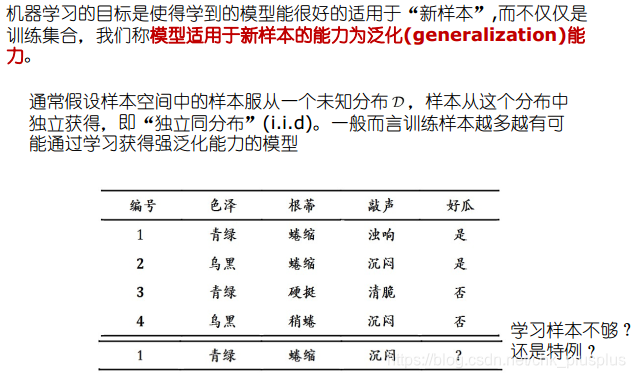
样本空间、假设空间、版本空间
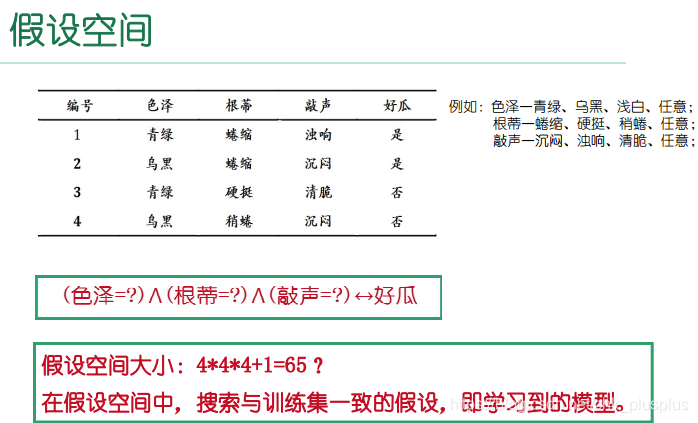
注意区分样本空间,假设空间与版本空间。
样本空间:
是属性张成的空间,比如这里属性都可以看成是离散值,一共3个属性,每个属性有三种取值,张成一个3维的样本空间,里边一共有3*3*3=27个样本点。这里这个样本空间非常小,但是在现实情况中,通常样本空间很大,样本集只是样本空间的一个很小的采样。样本空间在概率论中定义是随机事件的所有基本结果组成的集合,其实本质是一样的,我们假设样本空间中全体样本服从一个未知的分布,即一个随机事件对应的随机变量的分布,样本集中的所有样本都是独立地从这个分布中采样得到的,也可以看成是,该分布对应的随机变量的一系列取值。从这个角度来说,对于一个分布,采样得到不同样本的概率也是不同的。
假设空间:
是所有假设组成的空间,假设是什么?可以看成是一种对应于好瓜的属性的组合,即某几个属性组合一块对应好瓜。如下图,图中第一行3个属性都是通配符,第一行有一个假设,第二行中有1个属性不是通配符,2个属性是通配符,每个属性又有三种可能取值,所以先取1个通配符的那个属性,有3种取法,每个属性又有3种取值,所以一共有3*3=9个假设,第三行中,前两个属性都不是通配符,只有第三个是通配符,选两个不是通配符的,3选2有3种选法,每种选法中,两个非通配符各有3种取值,所以一共有3*3*3=27个假设。第四行所有属性都没用通配符,一共3*3*3=27种假设,再加上一种假设,即可能好瓜这个概念并不存在。所以一共有1+9+27+27+1=65 个假设。可以看出,假设空间是包含样本空间的,即样本空间包含在假设空间之中。
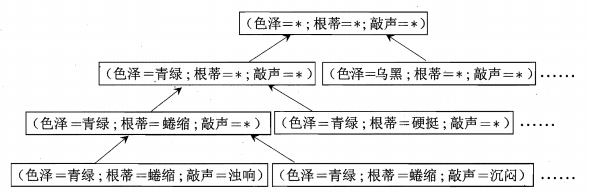
里边的每个方框都对应了一个假设,可以看到假设之间是存在着包含关系的,虽然有包含关系,但每一个方框是不同的假设,只不过不同的假设对于同一个新样本可以做出同样的预测。这里先提一下归纳偏好,有些学习算法可能倾向于归纳,有些可能倾向于细化,这就造成倾向归纳的学习器得到的假设是包含倾向细化的学习器的。需要注意的是,可能属性值是什么无所谓,所有瓜都是好瓜,不存在坏瓜这个概念,即对应了最上边一行的那个假设,按上图,假设空间中有C(4,1)*C(4,1)*C(4,1)=4*4*4种假设,但还有一种假设,即不存在好瓜这个概念,所以假设空间大小是4*4*4+1=65。与上边推论一样。
版本空间:
训练或学习过程就是通过学习算法搜索与训练集一致的假设,就是根据一定的搜索策略不断删除与样本不符合的假设,留些符合结论的假设。但实际情况中可能假设空间很大,但我们的训练样本很有限,因此可能存在多个与样本一致的假设的集合,我们把这个假设的集合称为版本空间。
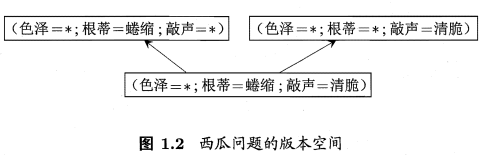
上图中表明最后只有这3个假设是符合样本集的。
需要注意的是当属性值为连续值时,在分类问题中,样本空间可能是无穷大的,假设空间也是无穷大,不同的算法可能搜索到的假设都不相同。在回归问题中,样本空间,输出空间都是无穷大的。
归纳偏好
![]()
上边版本空间中的三个假设,对于这个样本会给出不同的预测。
通过学习得到的模型对应了版本空间中的一个假设。这个学习得到的假设必须是确定的。即对于一个样本集,某个学习器学习得到的模型不能同时对应几个不同的假设,这样在每次面临同一个新样本的时候就可能导致不同的输出,这样的学习算法是无效的。即任何一个有效的学习算法必然有其归纳偏好,这个偏好使其从假设空间中选择了其中的一个假设。这就是归纳偏好。

奥卡姆剃刀原则:如无必要,勿增实体
但这个原则本就是有点主观的,什么是简单,什么是复杂,从不同的角度看可能是不同的。
需要注意的是,大多数时候,算法的归纳偏好是否与实际问题相匹配,决定了算法的性能。
没有免费午餐定理(NFL)



https://blog.csdn.net/u013238941/article/details/79091252
可以参考这篇博客,尤其其中关于求和h和求和f的理解。认为学习算法a基于某个样本集X可能产生多个假设h,只不过产生每个假设的概率值![]() 是不同的。还有对于目标函数f的理解,
是不同的。还有对于目标函数f的理解,
可以参考这个

根据西瓜书原话

所以,没有免费午餐定理意思是,对于同一个样本空间上的所有问题,即所有的目标函数f,任何算法哪怕瞎蒙,它们的期望性能都是一样的,但如果针对具体的一个目标函数f,即具体的学习问题,不同的算法性能是不一样的。
推导的时候假设所有的目标函数f是均匀分布的,但现实并非如此。